Prometheus、Thanos、Grafanaによる複数のOEクラスタの監視 - パート1 (2021/11/29)
Prometheus、Thanos、Grafanaによる複数のOEクラスタの監視 - パート1 (2021/11/29)
投稿者:Ali Mukadam
前回の記事では、Verrazzano用の複数のOKEクラスターを異なるOCIリージョンにデプロイしました。今度はそれらを監視したいと思います。
- Prometheus と Grafana のインストール
- Prometheus を入手し、メトリクスをスクレイピングするか、メトリクスをプッシュすることで、アプリケーションやワークロードを監視
- Grafana では、Prometheus をデータソースとして使用し、アプリケーションやワークロードの状態を把握するためのダッシュボードを作成
- AlertManagerを使用して、何か問題が発生したときに通知を受ける
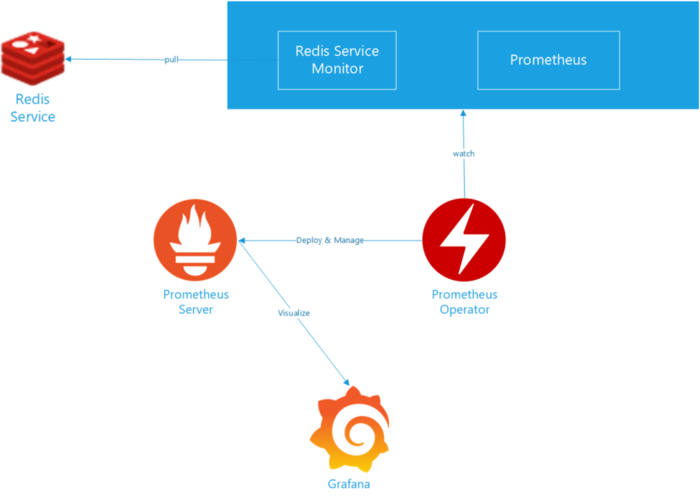
PrometheusとGrafanaによるRedisのモニタリング
Prometheusの1つの問題点は、シングルトンとして動作することです。これは、Prometheus がクラスタで動作しないことを意味しており、高可用性を得ることができません。Prometheus のインスタンスがあるホストがクラッシュした場合、その責務を果たす代替の Prometheus インスタンスがないため、大変なことになります。
上記の第一の問題をさらに悪化させる第二の問題は、Prometheusがメトリクスをディスクにローカルに保存することです。もしPrometheusインスタンスがクラッシュしたら、いくつかのメトリクスを失うことになります。もしその過程でディスクが破損してしまったら、バックアップを取っていない限り、すべてを失うことになります。
より良いソリューションが開発されるまでは、少なくとも2つ目のインスタンスを実行して、同じエンドポイントをスクレイピングさせ、Prometheusインスタンスが異なるホスト上で実行されるようにするという方法がありました。この方法では、高可用性が得られているように見えますが、Prometheus に上限が設定されているため、実際にはスケーラブルではありません。また、基本的に同じデータを2回スクレイピングすることになるので、効率も良くありません。では、どうすればPrometheusを高稼働させることができるのだろうか?
3つ目の問題は、Prometheusがデータを限られた時間しか保持しないことです。この CNCF のビデオは、この問題を非常によく説明しています。では、どうすればメトリクスの長期保存が可能になるでしょうか?
4つ目の問題は、複数のクラスターをどのように監視するかです。それぞれのクラスターにPrometheusのインスタンスを走らせ、それらをフェデレーテッド・モードでデプロイすることができます。私たちの4ノードのクラスターでは、シンガポールの管理クラスターが、シドニー、ムンバイ、東京の各リージョンにデプロイされたPrometheusサーバーの特定の時系列をスクレイピングすることになります。
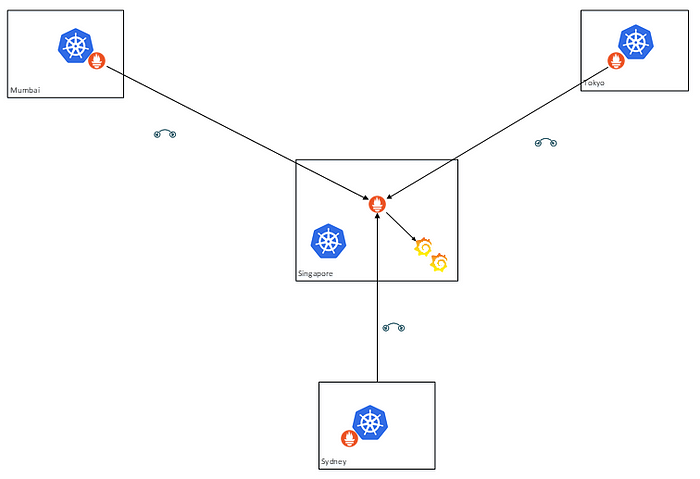
Federated Prometheus
とはいえ、Prometheusのインスタンスは1つのままです(これもシングルトンの問題です)。同じ時系列をスクレイピングする別のPrometheusインスタンスをいつでも追加することができます。
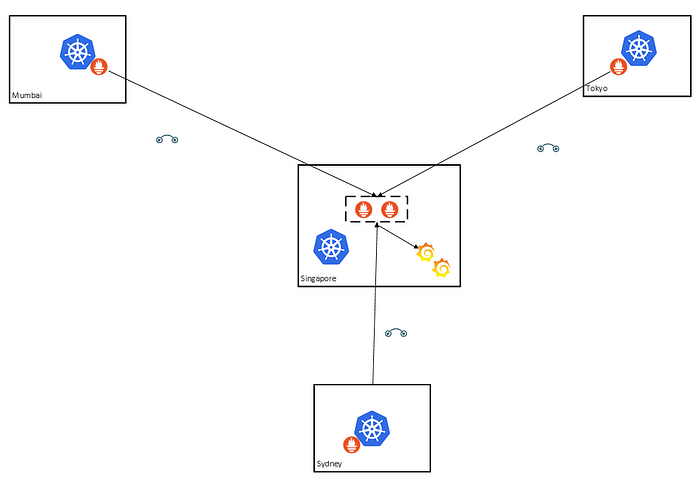
2つのPrometheusインスタンスが他のPrometheusサーバーと連携
繰り返しになりますが、これもあまり効率的ではありませんし、コストもかなり高くなります。また、長期保存の問題もまだ解決していません。
Thanosの登場です。
Thanosプロジェクトは、Prometheusに高可用性と長期的なストレージを提供することを目的としています。
この記事では、Prometheus、Thanos、Grafana を使って 1 つの OKE クラスタを監視する方法を見ていきます。次の記事では、複数のクラスターを追加する方法を見ていきます。
アーキテクチャ
Thanosのアーキテクチャを以下の図に示します。
Thanosアーキテクチャ(出典:thanos.io)
ご覧のように、このアーキテクチャには多くのコンポーネントがあり、興味のある方は、ここにそれぞれの役割についての非常に良い説明があります。
今回のセットアップのために、これを一部消化しておきます。
- Thanosサイドカーは、サイドカーコンテナとして、各リージョンのPrometheusポッドにデプロイされる。サイドカーはPrometheusのデータを読み込んでクエリを行い、TSDBブロックをオブジェクトストレージにアップロードします。そのため、ワーカーノードがオブジェクトストレージを呼び出せるようにする必要があり、サービスゲートウェイを介したルーティングが必要になります。これは OKE ワーカーノードの要件なので、サイドカーが TSDB ブロックを OCI オブジェクトストレージにアップロードできるようにするために何もする必要はありません。
- Thanos Store ゲートウェイは、オブジェクトストレージに保存されているメトリクスを照会し、その取得を可能にする API を提示します。デフォルトでは10901番ポートで待ち受けます。複数のクラスターを監視する場合は、関連するNSGを変更することで、このポートが開いていることを確認する必要があります。さて、信頼性の高いインターフェイスにしたいので、このゲートウェイをOCIロードバランサーを作成するLoadBalancerサービスとして作成したいと思います。さらに、これをプライベートなロードバランサーとし、プライベートなロードバランサーのサブネットにデプロイしたいと思います。そのため、内部のロードバランサーNSGを変更する必要があります。
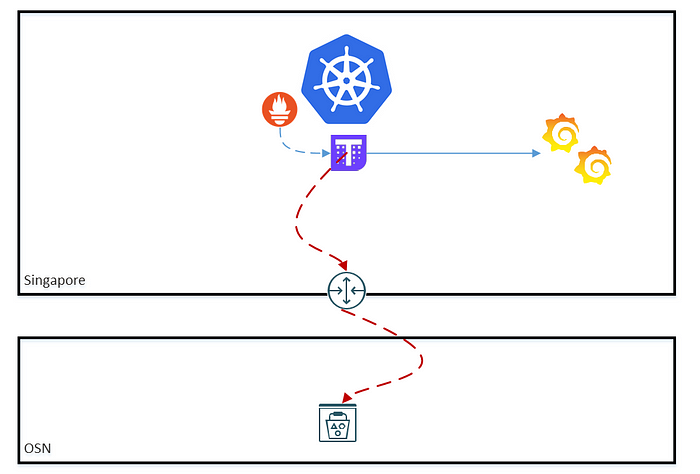
Thanosを1つのクラスターに
また、以下の点にも注意してください。
- Thanos が TSDB ブロックを 2 時間ごとにプッシュするという問題が残っています。
- 上記のアーキテクチャには、receiveコンポーネントを使ったバリエーションがあります。
しかし、これらについては次の記事で紹介します。今のところ、私たちの関心は高可用性と長期的なデータストレージの問題を解決することにあります。
オブジェクトストアの作成と使用
デプロイを行う前に、TSDBブロックを保存するためにOCI Object Storageにバケットを作成する必要があります。この記事を書いている時点では、ThanosとOCI Object Storageのネイティブな統合はまだありません。OCI Object Storageをデータストアの1つとするために、ThanosプロジェクトでGitHubにPRを公開しています。その日が来るまでは、OCIのS3インターフェースを代わりに使うことになります。鍵屋さんが言っていたように

"Always another way"
さて、S3インターフェースを使用するためには、Thanosの統合に使用するユーザーのCustomer Secret Keyを作成する必要があります。OCIコンソールにログインし、ユーザーアイコンをクリックし、Customer Secret Keysに移動します。「Generate Secret Key」をクリックします。
そして、そのキーを必ずコピーしてください。
秘密鍵の生成
次に、自分がアドミン・リージョン(ここではシンガポール)にいることを確認します。Storage > Object Storageに移動し、Bucketを作成します。
「thanos」という名前のバケットを作成します。
イメージ的にはthanosと呼んでいます。
Thanosオブジェクトストアの設定
次にやるべきことは、S3エンドポイントの設定です。S3互換APIはこちらにあります。
https://docs.oracle.com/en-us/iaas/api/#/en/s3objectstorage/20160918/
以下のようなフォーマットになっています。
<object_storage_namespace>.compat.objectstorage.region.oraclecloud.com
次にSingapore用のobjectstoreファイルを作成します。例:thanos-shin-storage.yaml
| type: S3 |
| config: |
| bucket: "thanos" |
| endpoint: "<namespace>.compat.objectstorage.<region>.oraclecloud.com" |
| region: "<region>" |
| access_key: "<my_access_key>" |
| insecure: false |
| signature_version2: false |
| secret_key: "<my_secret_key>" |
| put_user_metadata: {} |
| http_config: |
| idle_conn_timeout: 1m30s |
| response_header_timeout: 2m |
| insecure_skip_verify: false |
| tls_handshake_timeout: 10s |
| expect_continue_timeout: 1s |
| max_idle_conns: 100 |
| max_idle_conns_per_host: 100 |
| max_conns_per_host: 0 |
| trace: |
| enable: false |
| list_objects_version: "" |
| part_size: 67108864 |
| sse_config: |
| type: "" |
| kms_key_id: "" |
| kms_encryption_context: {} |
encryption_key: ""
エンドポイント、アクセスキー、シークレットキーの値を入れ替えます。アクセスキーは「ユーザープロファイル」→「カスタマーシークレットキー」のページにあり、シークレットキーは先ほど生成・保存したものです。そして、monitoringという名前のネームスペースを作成し、この設定をKubernetesのシークレットに保存します。
kubectl create ns monitoring
kubectl -n monitoring create secret generic thanos-objstore-config --from-file=thanos-sin-storage.yaml=thanos-sin-storage.yaml
Prometheusをクラスタにデプロイ
サイドカー付きの Prometheus をクラスターにデプロイします。
ここでは、Bitnami の優秀なスタッフが作成した kube-prometheus helm chart を使用します。bitnami helm repo を追加して helm update を実行します。
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo updatekube-prometheusのデフォルトマニフェストを生成します。
helm show values bitnami/kube-prometheus > prometheusvalues.yaml以下のヘルムチャートのプロパティを追加・変更する必要があります(イタリック:ヘルムマニフェストのプロパティのパスを示し、太字:OCIから取得してマニフェスト内で置き換える必要のある値を示します)。
prometheus.thanos.create: true
prometheus.thanos.objectStorageConfig.secretName: thanos-objstore-config
prometheus.thanos.objectStorageConfig.secretKey: thanos-sin-storage.yaml
prometheus.thanos.service.type: LoadBalancerprometheus.thanos.service.annotations: oci.oraclecloud.com/oci-network-security-groups: "nsg_id"
service.beta.kubernetes.io/oci-load-balancer-shape: "flexible"
service.beta.kubernetes.io/oci-load-balancer-shape-flex-min: "50"
service.beta.kubernetes.io/oci-load-balancer-shape-flex-max: "100"
service.beta.kubernetes.io/oci-load-balancer-subnet1: "subnet_id"
service.beta.kubernetes.io/oci-load-balancer-internal: "true"
service.beta.kubernetes.io/oci-load-balancer-security-list-management-mode: "All"prometheus.externalLabels:
cluster: "sin"
UPDATE:Terraformモジュールに(今発見された)欠落したルールがあるため、管理モードを「All」に変更しました。これにより、2つのルールがデフォルトのセキュリティリストに追加されます。
そして、Prometheusをインストールします。
helm install prometheus bitnami/kube-prometheus \
--namespace monitoring \
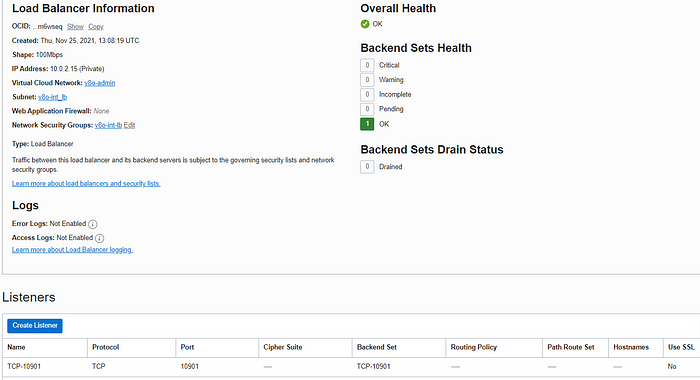
-f prometheusvalues.yamlPrometheusのデプロイを確認します。
- Prometheusによって、プライベートOCIロードバランサーが作成されていること
- ロードバランサーは10901番ポートにTCPリスナーを持っています。
- ロードバランサーは、内部ロードバランサーサブネットにデプロイされ、int-lb NSGが割り当てられていること
この時点で、内部ロードバランサーに関連するNSGを更新して、10901の受信TCPを受け入れるようにして、後で使用できるようにする方法が2つあります。
- terraform.tfvarsを更新し、internal_lb_allowed_portsパラメータを更新して10901番ポートを許可する。この後、再度terraform applyを実行する必要があります。
- または、OCIコンソールを使ってNSGに直接追加してください。UPDATE: 管理モードを「すべて」に変更したため、今のところこの作業は必要ありません。
4. セキュリティ面を強化したい場合は、以下のことが考えられます。
a. cert-managerを使ってSSL証明書を追加
b. 新しいWAF統合機能を使う。この場合、ロードバランサーをFlexibleに設定する必要があります。
5. オペレーターホストへのSSHトンネルを作成し、Prometheusのエクスプレッションブラウザをテストできるようにする。
ssh -L 9090:localhost:9090 -J opc@bastion_public_ip opc@operator_private_ip kubectl port-forward --namespace monitoring svc/prometheus-kube-prometheus-prometheus 9090:9090
6. Prometheusのexpression browserにアクセスします。http://localhost:9090/、クエリを実行します。
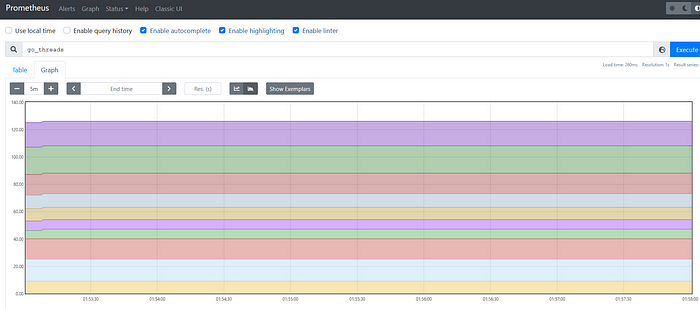
Prometheus式ブラウザ
Prometheusがデプロイされました。
クラスタにThanosをデプロイ
Thanos をデプロイする時が来ました。thanos helm chart を使用します。Thanos helm chartのデフォルトマニフェストを生成します。
helm show values bitnami/thanos > thanosvalues.yaml以下のヘルムチャートのプロパティを追加・変更する必要があります(イタリック:ヘルムマニフェストのプロパティのパスを示し、太字:OCIから取得してマニフェスト内で置き換える必要のある値を示します)。
objstoreConfig: |-
type: S3
config:
bucket: "thanos"
endpoint: "<namespace>.compat.objectstorage.<region>.oraclecloud.com"
region: "<region>"
access_key: "<my_access_key>"
insecure: false
signature_version2: false
secret_key: "<my_secret_key>"
put_user_metadata: {}
http_config:
idle_conn_timeout: 1m30s
response_header_timeout: 2m
insecure_skip_verify: false
tls_handshake_timeout: 10s
expect_continue_timeout: 1s
max_idle_conns: 100
max_idle_conns_per_host: 100
max_conns_per_host: 0
trace:
enable: false
list_objects_version: ""
part_size: 67108864
sse_config:
type: ""
kms_key_id: ""
kms_encryption_context: {}
encryption_key: ""query.enabled: true
query.stores:
# Private IP address of internal load balancer
- 123.123.123.123: 10901queryFrontend.enabled: true
bucketweb.enabled: true
compactor.enabled: true
storegateway.enabled: true
ruler.enabled: true
Thanosのデプロイ
helm install thanos bitnami/thanos \
--namespace monitoring \
-f thanosvalues.yaml検証します。
1. すべてのポッドが正常に動作している。
kubectl -n monitoring get pods2. Thanos Queryが正常に動作していること。
export SERVICE_PORT=$(kubectl get --namespace monitoring -o jsonpath="{.spec.ports[0].port}" services thanos-query) kubectl port-forward --namespace monitoring svc/thanos-query ${SERVICE_PORT}:${SERVICE_PORT}
http://localhost:9090にブラウザでアクセスする
Thanosへのアクセス クエリ
3. シンガポールの店舗が登録されています: http://localhost:9090/stores
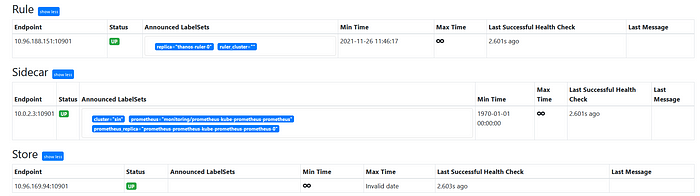
シンガポール店はレプリケートされている
上のスクリーンショットでは、External Labelsの "cluster=sin "が、シンガポールのVerrazzano管理クラスタを示していることもわかります。
Grafanaのデプロイ
最後のステップは、ThanosでGrafanaを使用することです。Thanosの開発者が行った数多くの巧みな設計上の決定の1つは、Prometheusと互換性のあるインターフェースを維持することでした。つまり、最小限の労力と変更で、Grafana で作成した既存のダッシュボードを使用することができるのです。
まずはhelmのリポジトリを追加しましょう。
helm repo add grafana https://grafana.github.io/helm-charts
helm repo updateそして、Grafanaをインストールします。
helm install --namespace monitoring grafana grafana/grafanaGrafanaのadminユーザーのパスワードを取得する必要があります。
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
GrafanaはデフォルトでClusterIPとしてインストールされているので、SSHでポートフォワードを行います。
ssh -L 3000:localhost:3000 -L 9090:localhost:9090 -J opc@bastion_public_ip opc@operator_private_ipkubectlを使用しています。
kubectl port-forward --namespace monitoring svc/grafana 3000:80ブラウザでGrafanaにアクセス http://localhost:3000/ ユーザー名「admin」と上記で取得したパスワードでログインします。
GrafanaとThanosの接続
Thanos と、Thanos が様々な Prometheii から取得しているメトリクスを使用するためには、まず Thanos をデータソースとして追加する必要があります。ThanosはPrometheusと同じインターフェースを提供していることを思い出してください。つまり、Prometheus プラグインを使って Thanos のデータソースを追加することができるのです。
- 左側の Configuration アイコンをクリックし、拡大したメニューから data source を選択
- 「Add data source」をクリックし、「Prometheus」を選択

Prometheusの選択
3. URLに「http://thanos-query.monitoring.svc.cluster.local:9090」を入力
4. 「Save & test」をクリックします。テストの結果、「Data source is working」と表示されるはずです。
Grafana への Kubernetes ダッシュボードの追加
Grafanaのダッシュボードを作成するために、Kubenetes Clusterのモニタリングダッシュボードをインポートすることにします。気になる方はもっと詳しいものがあります。これは素晴らしい作品ですが、私が唯一不満なのは、グラフの壁を作ってしまうことです。1つのKubernetesクラスタを監視するだけでも大変なのに、地理的に分散したクラスタ群を監視するのはもっと大変でしょうし、危機的状況でトラブルシューティングが必要になったときのことなど考えられません。ですから、私たちはもう少しシンプルさを求めています(いずれにしても主観的なものですが)。
- 左側の+アイコンをクリックし、展開されたメニューから「インポート」を選択
- ダッシュボードID:315を入力
- Loadをクリック
- 作成したPrometheus Data sourceが選択されていることを確認して、Importをクリック
これでKubernetesダッシュボードが表示されるはずです。
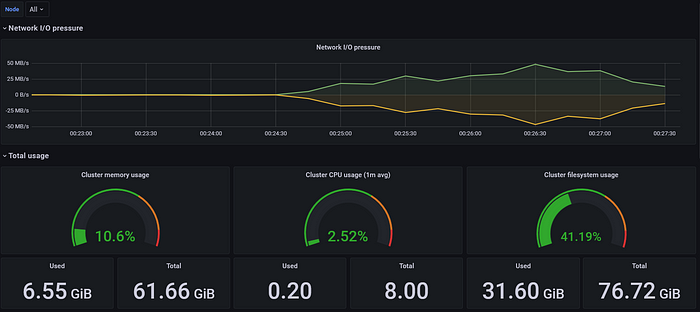 1 OKEクラスタのKubernetesダッシュボード
1 OKEクラスタのKubernetesダッシュボードこの時点で、PrometheusからThanosへのメトリクス取得がうまくいき、Thanosをデータソースとして使用できることがわかりました。しかし、これは1つのクラスタでしか動作せず、それもThanos自体をデプロイしたクラスタでの動作です。
パート2では、さらにクラスターを追加し、ダッシュボードを変更して、個々のクラスターを選択してそのメトリクスを分析できるようにします。
アップデート:Terraformモジュールにルールがないため、セキュリティリストの管理モードが「すべて」に変更されました。



コメント
コメントを投稿