OCI Data Flow (2022/07/08)
OCI Data Flow (2022/07/08)
https://medium.com/@majss/oci-data-flow-68079d396224
投稿者:Michał Wieleba

Tatra mountains (my photo)
今回は、OCIのビッグデータ機能を深堀りしてみたいと思います。その1つがData Flowです。これはクラウドベースのサーバーレスプラットフォームで、Sparkジョブを実行することができます。Sparkクラスタを手動で作成する必要がなく、ユーザーは簡単にData Flowにアプリケーションを投入し、実行することができます。
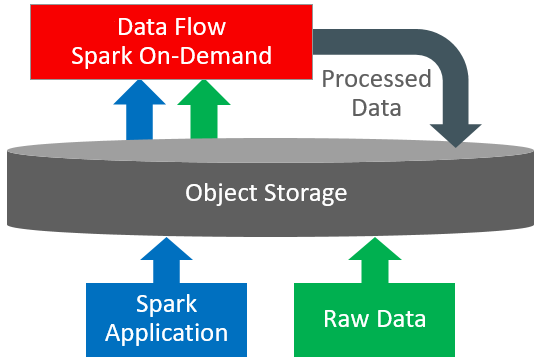
https://docs.oracle.com/en-us/iaas/data-flow/using/images/DF_Overview1.png
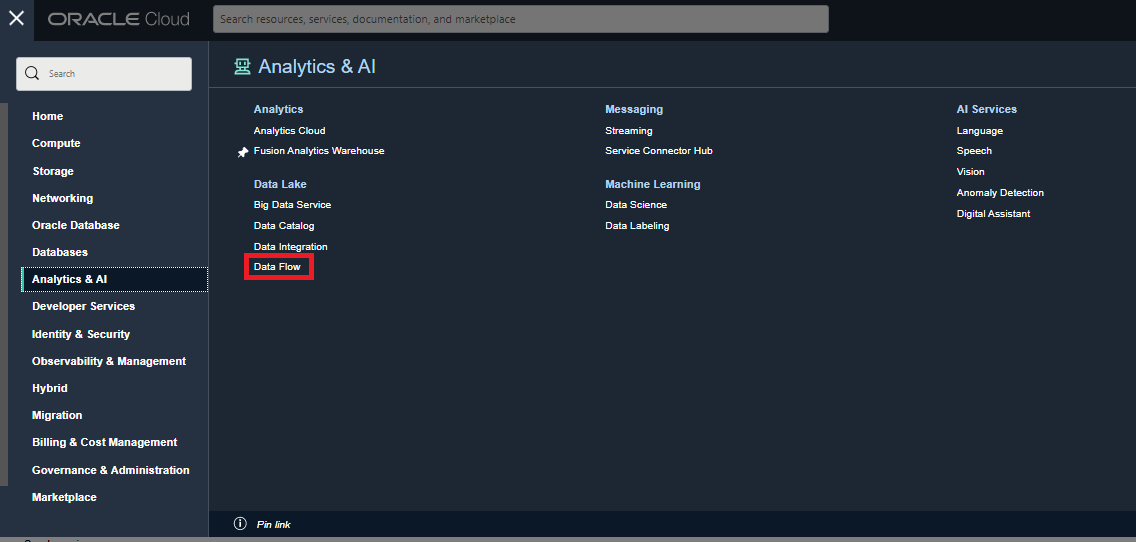
Data Flowサービスは、「アナリティクス&AI」ペインからアクセスすることができます。
最初のアプリケーションを作成する前に、いくつかの要件を満たしておく必要があります。dataflow-logsとdataflow-warehouseの2つのバケットと、dataflow-adminとdataflow-usersの2つのグループを作成しなければなりません。詳細な手順は以下の通りです。
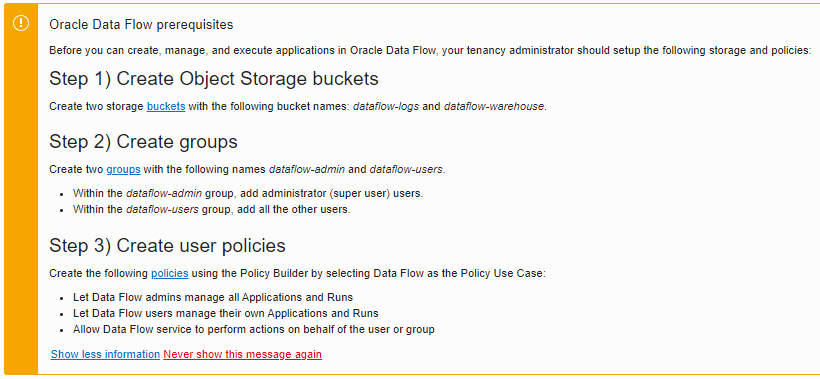
上記の手順が完了したら、最初のアプリケーションを作成する準備が整いました。
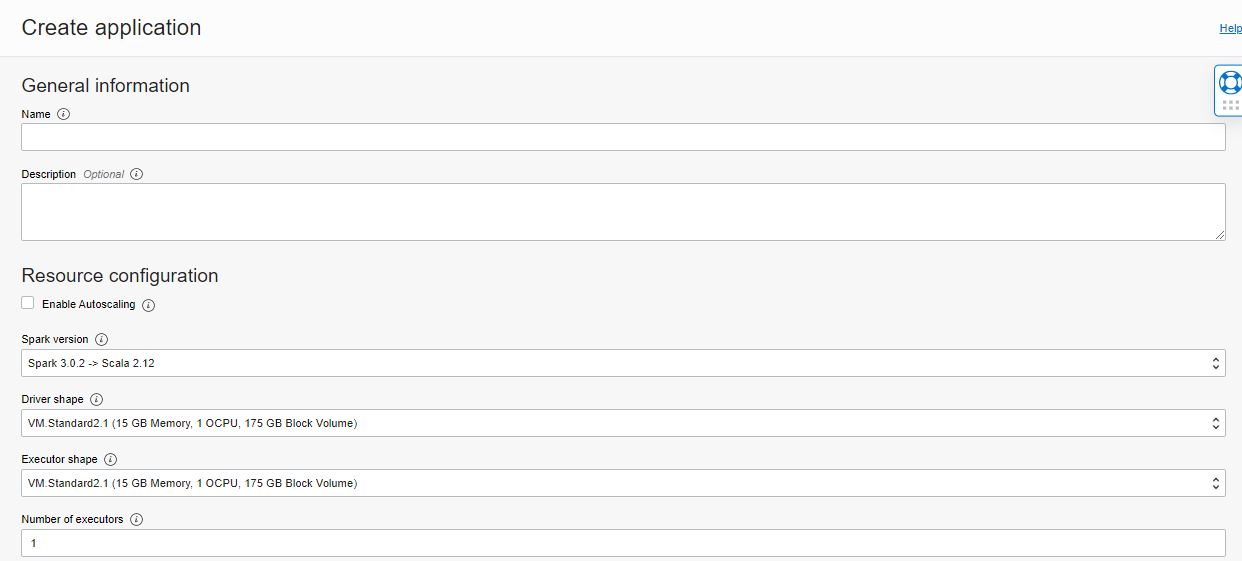
このプロセスは非常にシンプルです。まず、アプリケーション名とリソース構成を指定する必要があります。現在、2つのSparkバージョンが利用可能です。3.0.2 with Scala 2.12 と 2.4.4 with Scala 2.11 です。また、Sparkドライバとエグゼキュータの形状や、エグゼキュータ数など、ニーズに合わせて選択することができます。2022年6月1日現在、フレキシブルコンピュートシェイプが利用可能です(詳細:https://docs.oracle.com/en-us/iaas/data-flow/using/dfs_tips_for_app_default_size.htm#compute-shapes-flexible)。
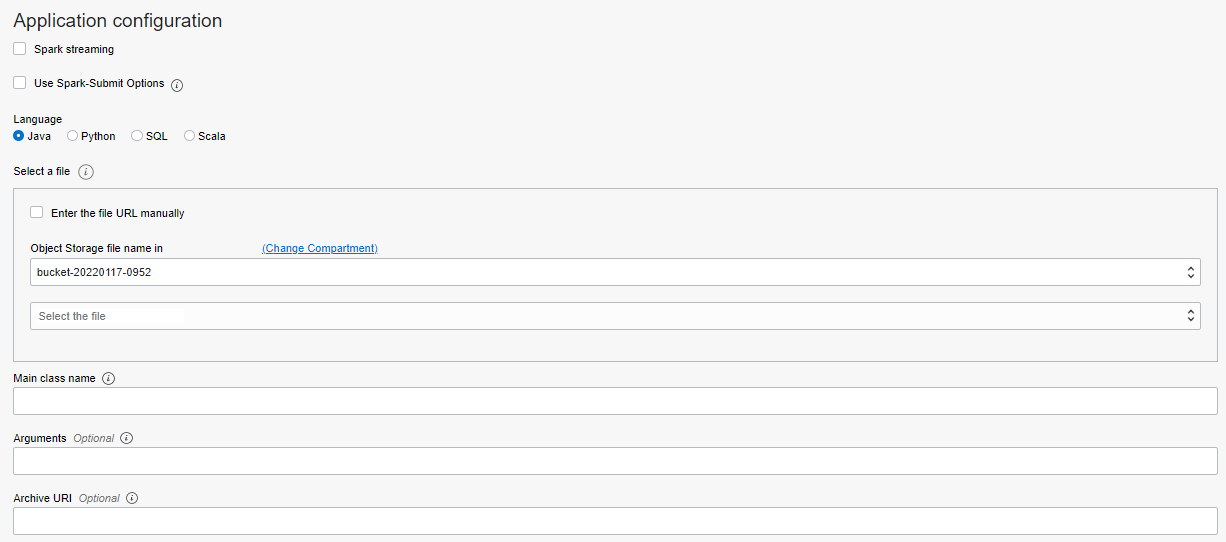
次ページ:アプリケーションの設定 このステップでは、Spark StreamingとSpark-Submitの機能を有効にすることができます。言語を選択し、実行ファイルのパスを指定することができます。メインクラスはアプリケーションを実行するためのものです。追加引数やライブラリ(オブジェクトストアにロードされるZIPファイル)も選択できます。
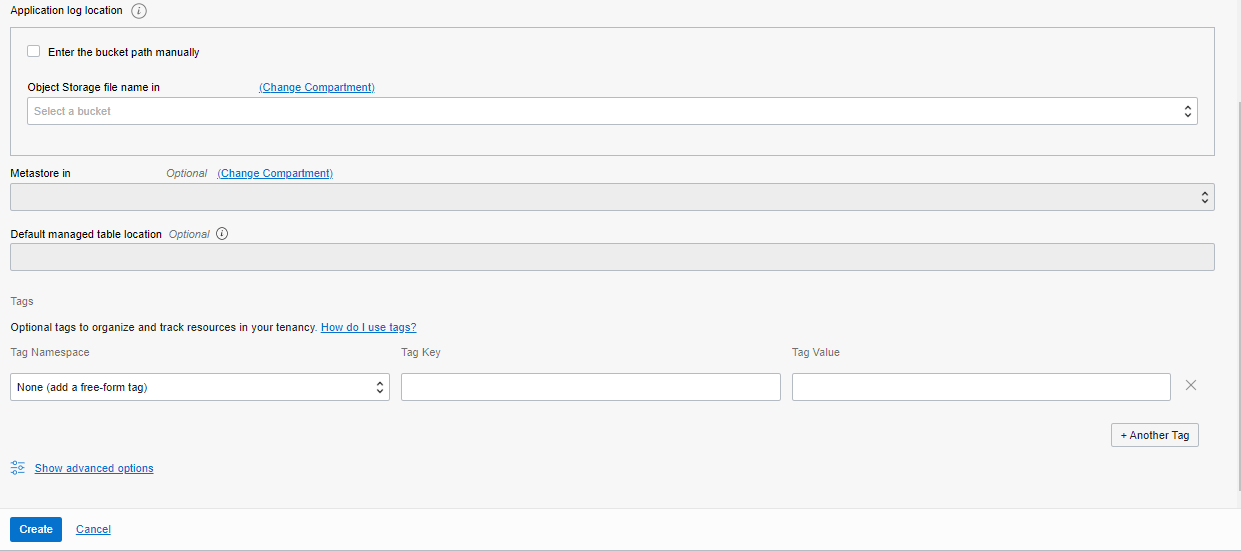
最後に、出力ログが格納されるオブジェクトストアのバケットへのカスタムパスを指定できます。Data Flowは、データカタログのリソースとしてHiveメタストアにアクセスし、スキーマ定義などを保存・取得することができます。オプションでタグを指定し、問題がなければ作成をクリックするだけです。
Data Flowはかなり期待できそうで、新機能もすぐにリリースされそうだ。アプリケーションの作成以外にも、Spark Streaming、Spark Oracle DataSource、Spark Dynamic Allocation、サイジングなど、カバーすべきトピックはたくさんあります。近々、これらのトピックを取り上げるつもりです。



{kind=link}
コメント
コメントを投稿