Infra as CodeによるOCIリソース作成をCloud ShellからTerraformで実施 (2022/12/30)
Infra as CodeによるOCIリソース作成をCloud ShellからTerraformで実施 (2022/12/30)
投稿者:Lucas Jellema
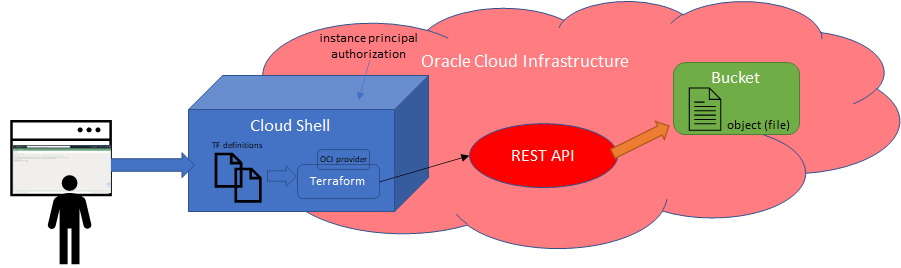
Oracle Cloud Infrastructure上のクラウドリソースの作成は、Terraform(plan)を使ってInfra as Codeとして行うのが理想的です。コンソールに手を触れる必要はなく、個々のユーザーにパーミッションを与える必要もなく、すべてのアクションをプレビューし、テストし、簡単に繰り返すことができるのです。OCI は Terraform を深くサポートしています。Terraform リソースに基づいたリソースの作成、更新、削除(OCI Provider for Terraform を通して)からスタック(それ自体がリソースとして定義された Terraform ベースの OCI リソースの定義済みコレクション)の作成、管理、実行、リソース発見を使った既存の OCI リソースからの Terraform リソース定義の作成まで、様々なことが可能です。
TerraformはOracle Cloud ConsoleからアクセスできるWebブラウザベースの端末で利用できる定義済みのVM、OCI Cloud Shellから最も簡単に利用することができます。Cloud Shellは無料で利用でき(月々のテナント制限内)、事前認証されたOracle Cloud Infrastructure CLIと、OCI Provider for TerraformによるTerraformを含むその他の便利なツールでLinuxシェルへのアクセスを提供します。Cloud Shell は "instance principal authorization" に該当し、OCI Configuration van Private Key pem file やその他の認証の設定なしに OCI Provider で Terraform を実行できることを意味しています。そのため、何もインストールする必要がありません。
今回はシンプルに、TerraformによるObject Storage Bucketの作成とそのBucket内のファイルの作成にフォーカスしてみます。Terraformの定義ができれば、それを何度でも適用して、指定したコンパートメントに同じ結果を出すことができますね。
次の記事では、このミニ星座を、私自身や他の人が再利用できるように、Terraformのリソースを知らなくても利用できるStackにする予定です。
TerraformのObject Storage BucketとFileの定義について
Terraformの定義ファイルをどのように整理するかについては、いくつかの考えや慣習があるようです。私は、最も一般的と思われるものに沿ってタグ付けしようとしています。これに関して決定的な真実を持っているとは言いません。4つのファイルを作成します。
- provider.tf - OCIプロバイダの構成(およびインスタンス・プリンシパル認証の起動)
- datasources.tf - OCI上のリソースを作成する際に使用する、OCIからデータを提供する「クエリオブジェクト」またはデータソースの定義(このファイルは、リソースの操作につながらない、データのクエリのみ)
- variables.tf - 他のファイルで使用される変数の定義。例えば、作成するバケツやオブジェクトの名前はこのファイルの変数として定義されている。なお、コマンドラインパラメータや環境変数を使って、実行時に変数の値を指定(上書き)することができます。
- storageBucketandObject.tf - 実際に管理するリソース(Object Storage上のBucketとObject)の定義。このファイルではデータソースと変数が使用される。また、出力定義を使ってその結果の一部を報告します。
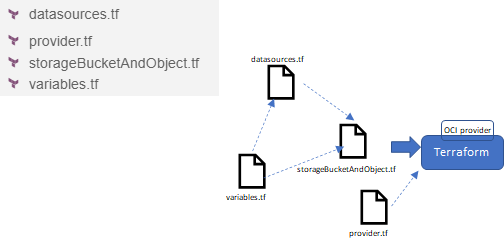
Note: Terraformはこれらの個々のファイルには関心を持ちません。名前もです。変な名前の1つのファイルに全部定義してしまったのと同じです。Terraformは気にしません。指定されたディレクトリにある拡張子が.tfのファイルから、すべての定義をメモリにロードして処理を開始するだけです。このファイル構造は、純粋に人間が読むためのものです。読みやすさと保守性、そしておそらくは再利用のためです。
注:ここで説明されているソースは、GitHubのここで入手できます。
実際にTerraformで管理するリソースを記述したファイル(storageBucketandObject.tf)は以下のような感じです。
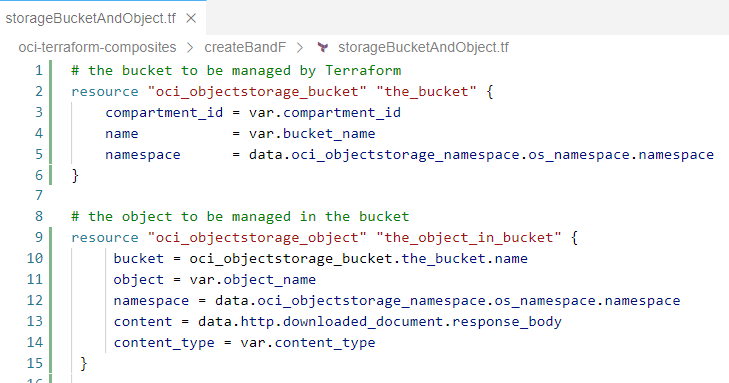
最初のリソースは oci_objectstorage_bucket というタイプで、Terraform 用 OCI Provider が認識し、処理方法を知っているタイプです。リソース定義の名前はthe_bucketです。これは作成されるバケットの名前ではなく、このコードブロックに対するTerraform内部のラベルです。一方、バケツの名前は variables.tf で定義されている var.bucket_name という変数から取得します。バケットを管理するコンパートメントも変数 (var,compartment_id) から取得します。名前空間は、データソース(datasources.tf ファイル)から取得します。
ここで定義される2つ目のリソースは、バケット内に生成されるオブジェクトです。内包するバケットへの参照は、リソースthe_bucketへの参照を通じて定義されます(oci_objectstorage_bucket.the_bucket.nameのように)。この参照は、Terraformのロジックにおいて、the_object_in_bucketのthe_bucketへの依存関係を確立するものでもあります。Terraformはオブジェクトに目を向ける前に、まずバケツのリソースに対して作業を行います。
オブジェクトの名前とコンテンツタイプは変数から、名前空間はデータソースから、コンテンツは別のデータソースから取得します: data.http.downloaded_document.response_body.
データソースの定義を見てみましょう - datasources.tfにあります。

データソース downloaded_document は Terraform http プロバイダ - 一般的な HTTP サーバーと対話するためのユーティリティプロバイダ - を使用します。このプロバイダは、指定された URL にあるドキュメントの内容を取得するために使用されます。注意: 現在、このリソースは text/* または application/json コンテントタイプで応答する URL からのみデータを取得することができ、返されるコンテントタイプヘッダーに関わらず結果は UTF-8 でエンコードされていることが期待されます。
GET リクエストの結果は data.http.downloaded_document.response_body として利用可能です。そしてそれは、リソース oci_objectstorage_object.the_object_in_bucket の定義で使用される参照です。
variables.tfファイルは大きな驚きではないでしょう:それは、今説明したファイルで参照される変数を定義しています。
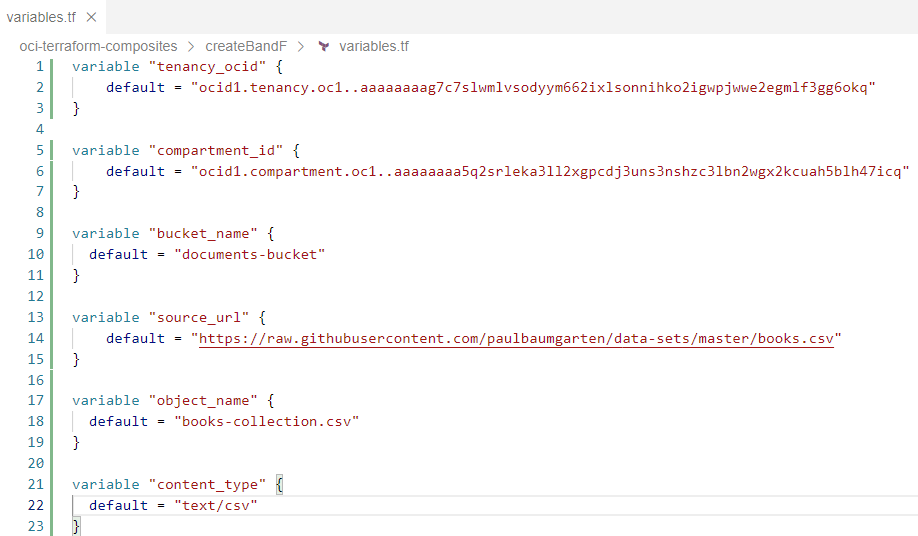
OCI Terraformスクリプトでは、tenancy_ocidとcompartment_idという変数がよく使われます。これらは、リソースを管理するテナンシーとコンパートメントを指定します。
変数bucket_nameには、このTerraformの設定全体で操作するBucketの名前が入ります。変数source_urlには、OCI Object Storage上のte bucketに作成されたオブジェクトのコンテンツを提供するために取得されるドキュメントのURLが格納されています。ここでは、書籍のレコードを含むCSVドキュメントのGitHub上のURLが設定されています。content_type変数はまさにそれを示しており、バケットにオブジェクトを作成する際に使用されます。text/csvに設定されていますが、Terraformプラン適用時にコマンドラインパラメータや環境変数で上書きすることが可能です。object_name 変数は、管理するオブジェクトに使用する名前を指定します。
最後に provider.tf というファイルで、Terraform がこれらのリソース定義を処理する際に利用する OCI プロバイダを定義します。
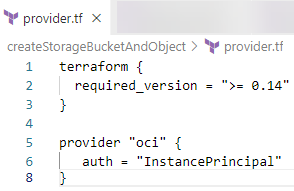
プロバイダは、OCI Cloud Shell 上で実行される場合、InstancePrinicipal 認証を利用します。
これらのファイルを配置して、いろいろと試してみましょう。リポジトリをローカルにクローンします。

続いて、Terraformを初期化します。
terraform init
を実行し、最終的に出力します。
次に、プランが正しいかどうかを試してみましょう - 実際にリソースを操作することなくです。
terraform plan

プランアクションからの出力は順調のようです。バケットが作成され、ダウンロードしたCSVファイルの内容でオブジェクトが作成される。私たちは満足することができます。
これでうまくいく確信が持てたので、次のステップに進み、本当に計画を適用してみましょう。
terraform apply
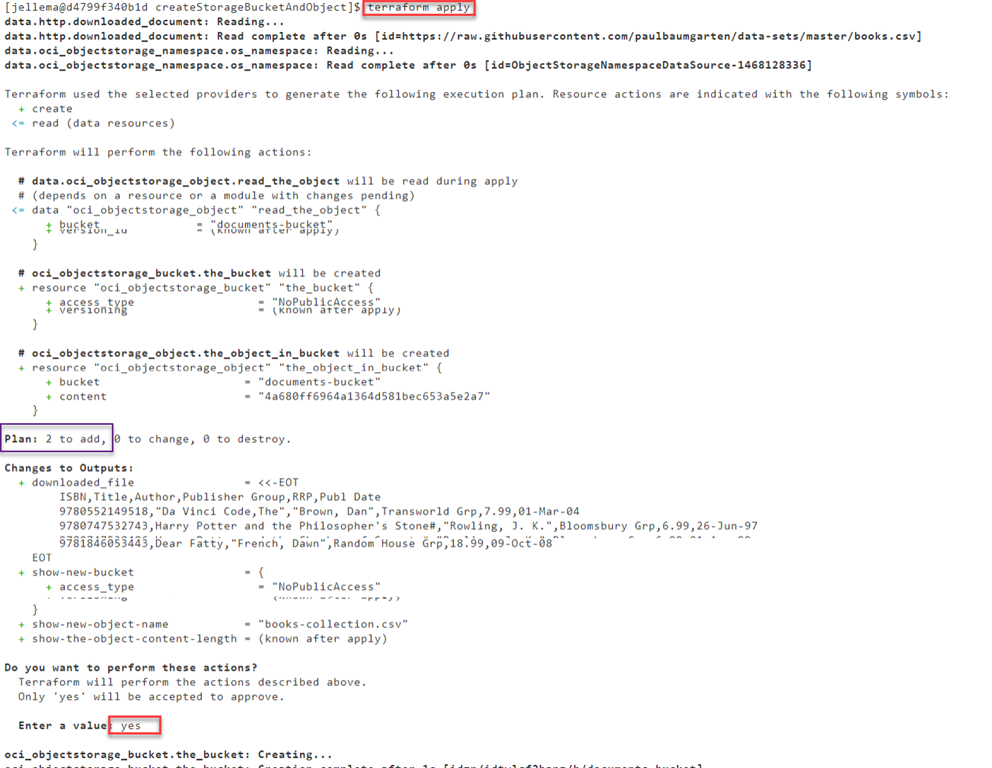
Terraformに変更を反映させることを確認するためにyesを入力すると、リソースのプロビジョニングが行われます。
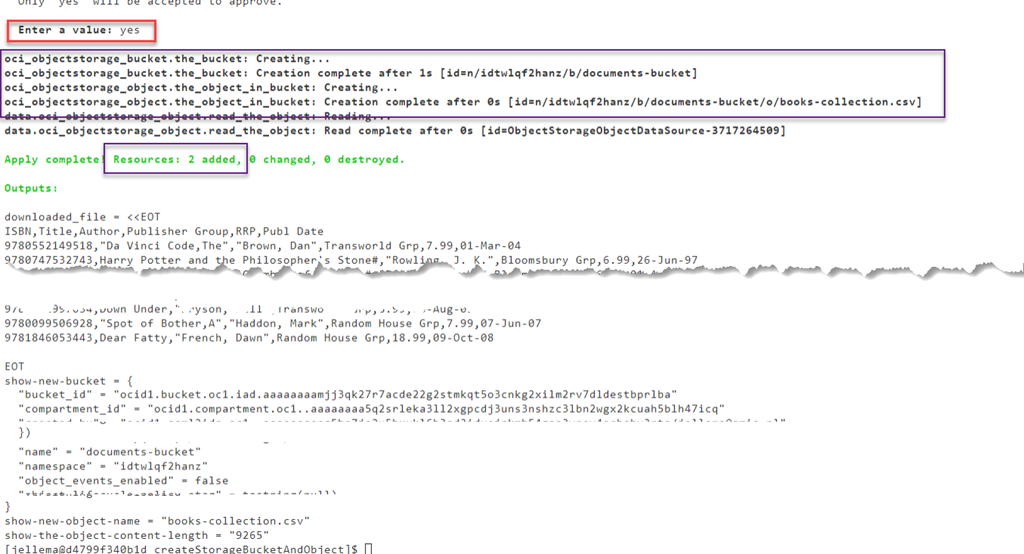
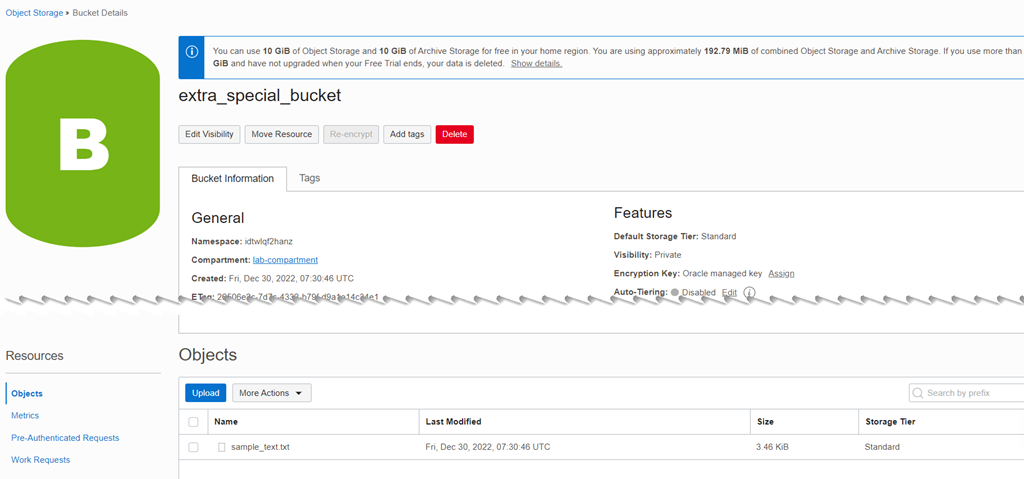
もちろん、バケットとオブジェクトが本当に作成されたかどうかは、コンソールで確認することができます。
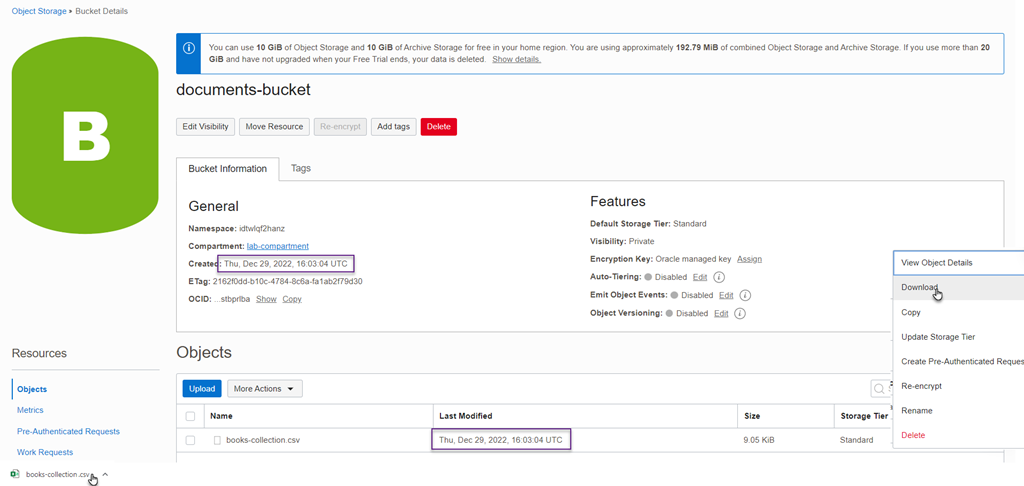
対象物の3つの点をクリックし、ポップアップメニューの「ダウンロード」をクリックし、最後にダウンロードしたファイルをクリックして、ブックレコードを含むCSV文書であるかどうかを確認します。

これは、Terraform Infrastructure as Code プランを実行することで、バケットが作成され、その中に GitHub 上のファイルからダウンロードした内容のオブジェクトが置かれていることを証明しています。
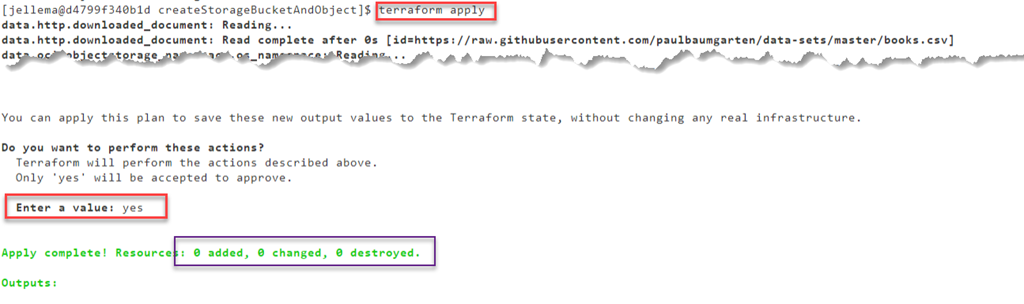
Note: Terraformのプランは、望ましい状況を記述します。アクションを実行するための指示は含まれていません。リソースを処理するプロバイダは、希望する状況を実現するためにどのアクションを実行すればよいかを知っていることが前提です。このことは、望ましい状況がすでに出来上がっている場合、計画を適用し直しても何も変わらないことも意味しています。すぐにもう一度terraform applyを実行しても、何も変わりません。
Object Storage のオブジェクトを別の URL で作成し、オブジェクトやバケットの名前も別のものにしたい場合、もちろん variables.tf の値を変更することができます。あるいは、tf ファイルをそのまま使用して、コマンドラインから値を上書きすることもできます。
terraform apply -var bucket_name=’extra_special_bucket’ -var object_name=’sample_text.txt’ -var source_url=’https://filesamples.com/samples/document/txt/sample3.txt’ -var content_type=’text/plain’
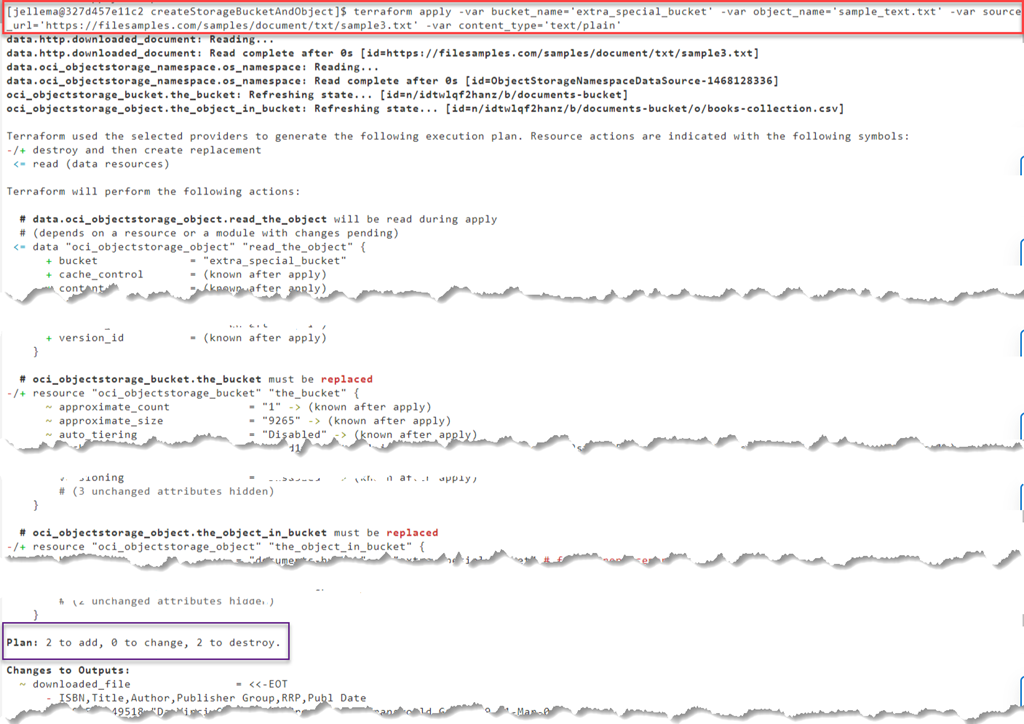
yesを入力すると、先に作成されたバケットとオブジェクトが削除され、新しいバケットとオブジェクトが作成されます(代わりに)。
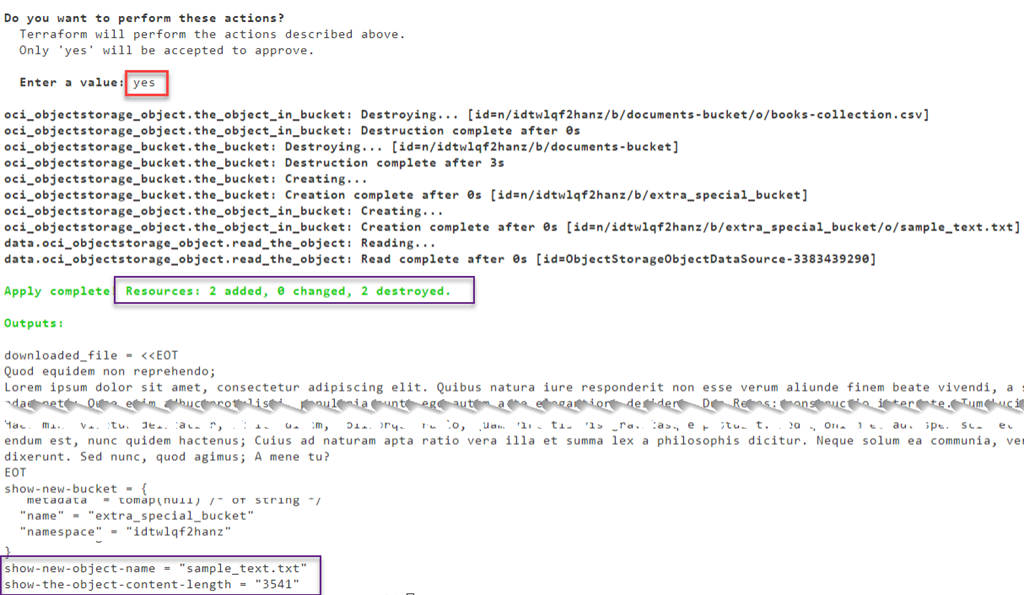
コンソールでは、次のような結果になります。
リソース
Sources in GitHub for this article
Working with Cloud Shell – OCI D0cs
OCI Provider for Terraform – Introduction (OCI Docs)
OCI Provider for Terraform – Reference (Terraform Docs)
Using Terraform variables (and providing values at runtime)
File Samples https://filesamples.com/formats/txt



コメント
コメントを投稿