Oracle Autonomous Databaseフィードの強化: データ統合を合理化するための継続的な改善 (2024/12/20)
Oracle Autonomous Databaseフィードの強化: データ統合を合理化するための継続的な改善 (2024/12/20)
https://blogs.oracle.com/datawarehousing/post/improvements-for-streamline-data-integration
投稿者: Alexey Filanovskiy | Product Manager
2年前、オブジェクト・ストアからデータベースに絶え間ないデータ・ロードを合理化するように設計された革新的な機能であるOracle Autonomous Database Feedが導入されました。発売以来、フィードはデータベースの専門家にとって不可欠なツールとなっています。今日、この機能によって、さらに高い効率でユーザーがどのように強化されているかを反映するために、ナラティブをリフレッシュしています。
Oracle Autonomous Databaseのフィードとは
Oracle Autonomous Databaseフィードは、オブジェクト・ストアからデータベースへの絶え間ないデータ・フローを合理化するように設計された一元化されたツールのままです。この機能では、次の2つのデータ統合モデルがサポートされています。
- プッシュ・モデル: 新しいデータが使用可能になると、通知はOCIオブジェクト・ストアから直接トリガーされます。
- プル・モデル: データは定期的にフェッチされるため、即時トリガーがなくても定期的に更新できます。
Feedは、Oracle Autonomous Database Data Studioツールキットにシームレスに統合され、データフローへの一元的な可視性、簡単なデバッグのための詳細なログ、ユーザーの労力を最小限に抑える明確で直感的なインターフェイスを提供することで、監視と管理を簡素化します。
フィードを使用する理由
今日のデータドリブンの世界では、企業はタイムリーで正確な情報で成功を収めています。多くの場合、これは、顧客トランザクション、IoTセンサー、運用ログなど、外部ソースからデータを継続的に取り込み、分析にすぐに使用できるようにすることを意味します。堅牢なフィード・メカニズムにより、データがデータベースにシームレスに流れるようになり、インサイトを最新かつ実用的なものに保つことができます。Oracle Autonomous Databaseのフィード機能が輝く場所です。これは、オブジェクト・ストアからADBへの更新の絶え間ないストリームを処理するように設計された自動データ・パイプラインと考えてください。
フィードは、次のものを提供することで、現代のビジネスのニーズに対応するように進化しました。
- プッシュおよびプル柔軟性: ワークロード要件に応じて、プッシュ・モデルを介したリアルタイム通知またはプル・モデルを介した定期的な更新のいずれかを選択します。
- APIコード生成: 直感的なUIにより、データ・パイプラインを簡単に構築できます。たとえば、ユーザーは、顧客トランザクション・ファイルをデータベースにロードするパイプラインを構成し、生成されたコードを再利用して、他のデータセットに対する同様のタスクを自動化できます。さらに、フィードは再利用可能なコードを生成し、従来のブラックボックス・ソリューションを超えた透明性と柔軟性をユーザーに提供します。
- トラブルシューティングの簡素化: 簡潔で実用的なログで問題をすばやく特定して解決します。
- 可視性の一元化: 1つの直感的なダッシュボードから重要なすべての更新にアクセスします。
- ユーザビリティの強化: フィルタリングおよび検索機能の改善により、カスタマイズされたイベント追跡を実現します。
仕組み
ステップ1: ログインして開始
まず、Oracle Autonomous Database Data Studioにログインします。表示されたら、「データ・ロード」セクションにナビゲートし、「フィード・データ」ダッシュボードを見つけます。そこで魔法が起こります!

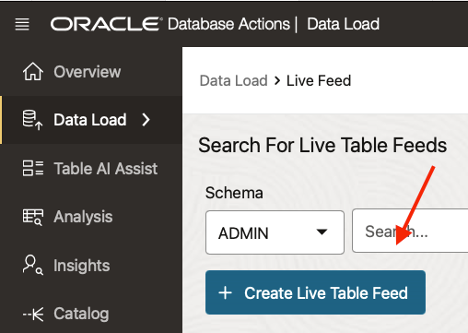
ステップ2: ライブ・フィードの作成
「ライブ・フィードの作成」をクリックして設定を開始します。
- クラウド・ストアの選択: データが存在するクラウド・ストアを選択します。フォルダやファイル拡張子などのフィルタを適用して、必要なものを正確にターゲットにできます。

- 表の指定: 次に、データを右側の表にマップします。列の名前と型を再確認して、すべてが完全に揃っていることを確認します。

ステップ3: プレビューと完璧
コミットする前に、プレビュー機能でデータを簡単にご確認ください。すべてが期待どおりに見えるように、これを「最後のコール」と考えてください。

ステップ4: 同期モデルの選択
次に、データのフローを決定します。
- プッシュ・モデル: リアルタイムの更新に最適です。
- プルモデル: 定期的な同期に最適です。ここでは、データをリフレッシュする時期のスケジュールも設定します。
ステップ5: モニターとリラックス
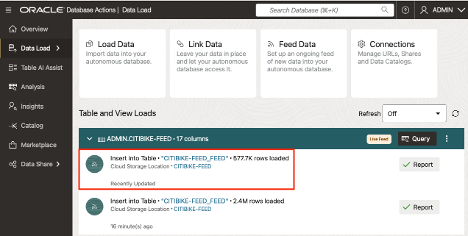
ライブフィードを設定したら、実行してください! 最初のデータ・ロードが発生し、その後、クラウド・バケットに表示される新しいファイルは自動的にデータベースと同期されます。追加作業は必要ありません。フィードの進捗とパフォーマンスをダッシュボードで直接追跡します。詳細なログを使用すると、アクティビティの監視、問題のトラブルシューティング、知識の維持が簡単になります。
Why You'll Love The Feedシングル
- エフォートレスなデータ統合: 手作業によるアップロードと中断に別れを告げましょう。データは、オブジェクト・ストアからデータベースにシームレスに流れます。
- 直感的なインタフェース: ここに複雑な設定や急な学習曲線はありません。合理化されたUIにより、手軽に作業を開始できます。
- Debugging Made Simple: トラブルシューティングはもはや推測ゲームではありません。詳細なログと実用的なインサイトにより、問題の解決は迅速かつ容易です。
- 再利用可能なコード、フルコントロール: フィードは単なる自動化ではなく、能力を強化します。再使用可能で透過的なコードを生成することで、パイプラインを必要な方法で柔軟に適応および制御できます。
まとめ
Oracle Autonomous Databaseのライブ・フィードは、データの統合と管理を合理化する強力なツールとして、時間のテストに立ってきました。将来を見据えて、柔軟で効率的なデータフローの提供におけるフィードの役割は拡大し続け、データドリブンなビジネスの要求に追随します。
あなたがまだフィードを探検していないなら、今が時間です。プッシュおよびプル統合モデル、簡単なパイプライン作成、再利用可能なコード、監視のための詳細なログなどの機能により、フィードはシームレスなデータ統合のための主要なツールです。Oracle Autonomous Database Data Studioに今すぐログインして、違いを確認してください。詳細については、公式ドキュメントを参照してください。


コメント
コメントを投稿