SQLからGraphQLへ: Oracle AI Database 26aiでのネイティブGraphQLサポートの確認 (2025/01/14)
SQLからGraphQLへ: Oracle AI Database 26aiでのネイティブGraphQLサポートの確認 (2025/01/14)
投稿者:Sathishkumar Rangaraj | Master Principal Solution Architect
前回の記事の続きとして、実際のテーブル関係を使用して、サブクエリや結合など、従来の SQL と直接同等に使用できる Oracle AI Database 26ai の実用的な GraphQL クエリについて説明します。これにより、複雑なリレーショナル ロジックを GraphQL でわかりやすく直感的に表現できるようになることがわかります。
これを説明するために、3つの共通するテーブルを使用します。テーブル定義の参照リンク
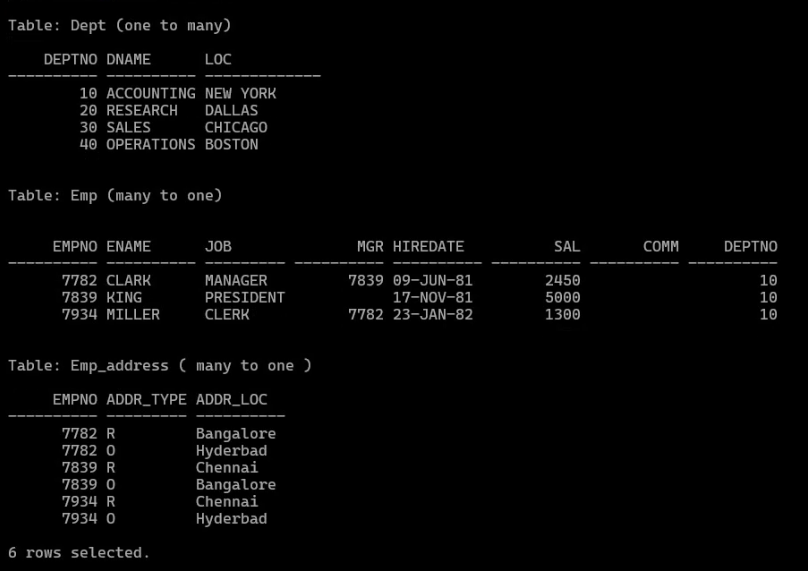
ユースケースの概要
要件:
従業員の詳細に加え、部署名、勤務先(O)、住所( )を取得します。部署番号10Rに所属する従業員をフィルター処理します。
従来のSQLアプローチ - サブクエリの使用
一般的な SQL アプローチは、相関サブクエリを使用して複数のテーブルから関連データを取得することです。
SELECT e.ename, e.hiredate, (SELECT d.dname FROM dept d WHERE d.deptno = e.deptno) AS dname, (SELECT a.addr_type FROM emp_address a WHERE a.empno = e.empno AND a.addr_type = 'O') AS Oaddr_type, (SELECT a.addr_loc FROM emp_address a WHERE a.empno = e.empno AND a.addr_type = 'O') AS Oaddr_loc, (SELECT a.addr_type FROM emp_address a WHERE a.empno = e.empno AND a.addr_type = 'R') AS Raddr_type, (SELECT a.addr_loc FROM emp_address a WHERE a.empno = e.empno AND a.addr_type = 'R') AS Raddr_loc FROM emp e WHERE e.deptno = 10;
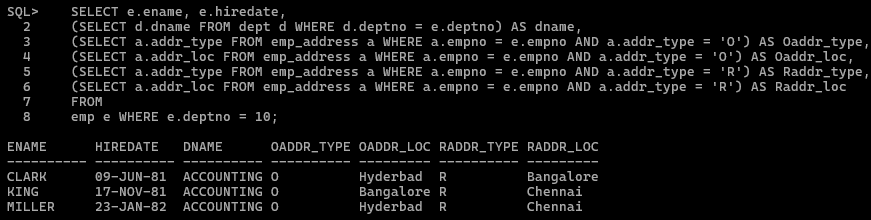
従来のSQLアプローチ - 結合の使用
同じ要件は結合を使用して実装することもできます。
SELECT e.ename, e.hiredate, d.dname, a.addr_type, a.addrloc FROM emp e JOIN dept d ON e.deptno = d.deptno JOIN emp_address a ON e.empno = a.empno WHERE d.deptno = 10;
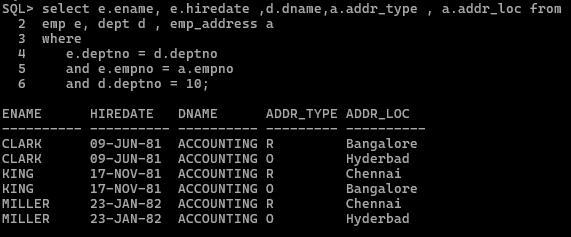
どちらのアプローチも
- 高度なSQLの専門知識が必要
- 関係が深まるにつれて、維持することが難しくなります。
Oracle Database 26aiにおけるネイティブGraphQLアプローチ
次に、結合、サブクエリ、ミドルウェアを使用せずに、データベース内で直接実行される GraphQL を使用して同じロジックを表現する方法を見てみましょう。
Oracle のネイティブ GRAPHQL() テーブル関数を使用すると、クエリは次のように記述できます。
select json_serialize(data pretty) as GraphQL_JSON from graphql('emp @alias (as: e) @where (sql : " deptno = 10 ") { ename, hiredate, deptName :dept{dname}, empAddressDetails : emp_address {addr_type, addr_loc}}' );
この単一の GraphQL クエリは、実質的に次のものを置き換えます。
- 相関サブクエリ
- 複数テーブルの結合

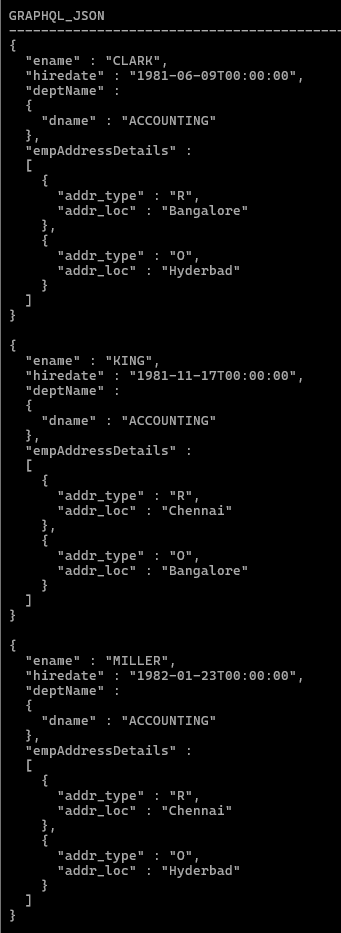
主な利点:
- 宣言的かつ直感的 -従業員、その部署、住所などの階層型データ モデルを直接表現します。
- 結合ロジックは不要 – 開発者は結合条件や外部キーを理解する必要はありません。Oracleが関係を自動的に解決します。
- JSONネイティブ出力 – 結果は構造化されたJSONとして返され、APIやフロントエンドフレームワークで利用できます。
- データベース レベルの実行 - クエリ全体がデータベース内で実行されるため、Oracle のオプティマイザー、セキュリティ、パフォーマンス チューニングのメリットを享受できます。
例: 2
これをさらに一歩進めて、より複雑な現実世界のクエリ、つまり次の要素を組み合わせたものを見てみましょう。
- 従業員の詳細
- 部署名
- オフィスと住居の住所
- マネージャー名(自己参照関係)
- 各従業員の報告先のリストを作成し、部門番号 10に属する従業員をフィルターします。
この種の要件は、HR および組織のレポート システムでは非常に一般的であり、従来は長くて複雑な SQLになります。
SQLアプローチ - 複数の相関サブクエリの使用:
SELECT e.ename, e.hiredate, (SELECT d.dname FROM dept d WHERE d.deptno = e.deptno) AS dname, (SELECT a.addr_type FROM emp_address a WHERE a.empno = e.empno ND a.addr_type = 'O') AS Oaddr_type, (SELECT a.addr_loc FROM emp_address a WHERE a.empno = e.empno AND a.addr_type = 'O') AS Offc_loc, (SELECT a.addr_type FROM emp_address a WHERE a.empno = e.empno AND a.addr_type = 'R') AS Raddr_type, (SELECT a.addr_loc FROM emp_address a WHERE a.empno = e.empno AND a.addr_type = 'R') AS home_loc, (SELECT m.ename FROM emp m WHERE m.empno = e.mgr) AS manager, NVL( (select LISTAGG(r.ename, ', ') WITHIN GROUP (ORDER BY r.ename) FROM emp r WHERE r.mgr = e.empno),'No Reportees' ) AS reportee_list FROM emp e WHERE e.deptno = 10;
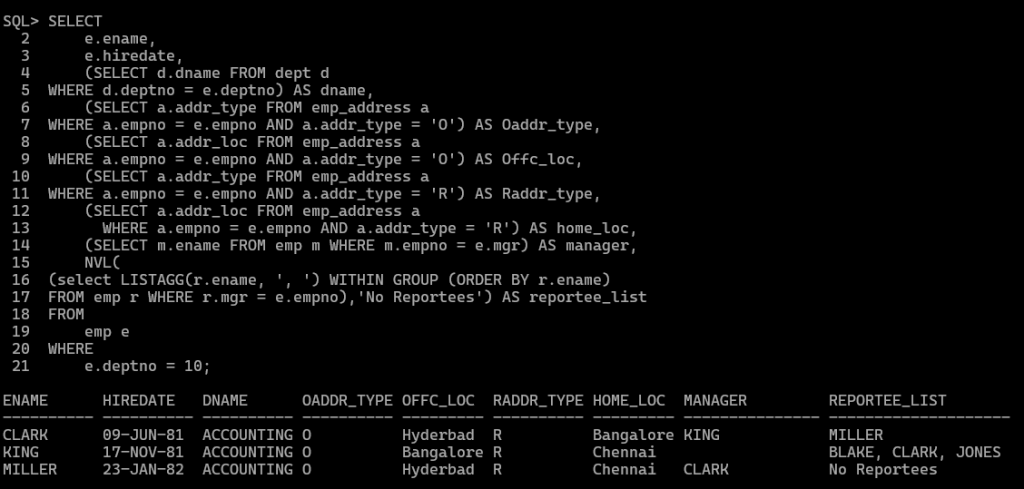
SQLアプローチ - 複数の結合の使用
SELECT e.ename, e.hiredate, d.dname, oa.addr_type AS Oaddr_type, oa.addr_loc AS Offc_loc, ra.addr_type AS Raddr_type, ra.addr_loc AS home_loc, m.ename AS manager_name, NVL(r.reportee_list, 'No Reportees') AS reportee_list FROM emp e JOIN dept d ON e.deptno = d.deptno LEFT JOIN emp_address oa ON e.empno = oa.empno AND oa.addr_type = 'O' LEFT JOIN emp_address ra ON e.empno = ra.empno AND ra.addr_type = 'R' LEFT JOIN emp m ON e.mgr = m.empno LEFT JOIN ( SELECT r.mgr, LISTAGG(r.ename, ', ') WITHIN GROUP (ORDER BY r.ename) AS reportee_list FROM emp r GROUP BY r.mgr ) r ON e.empno = r.mgr WHERE e.deptno = 10;
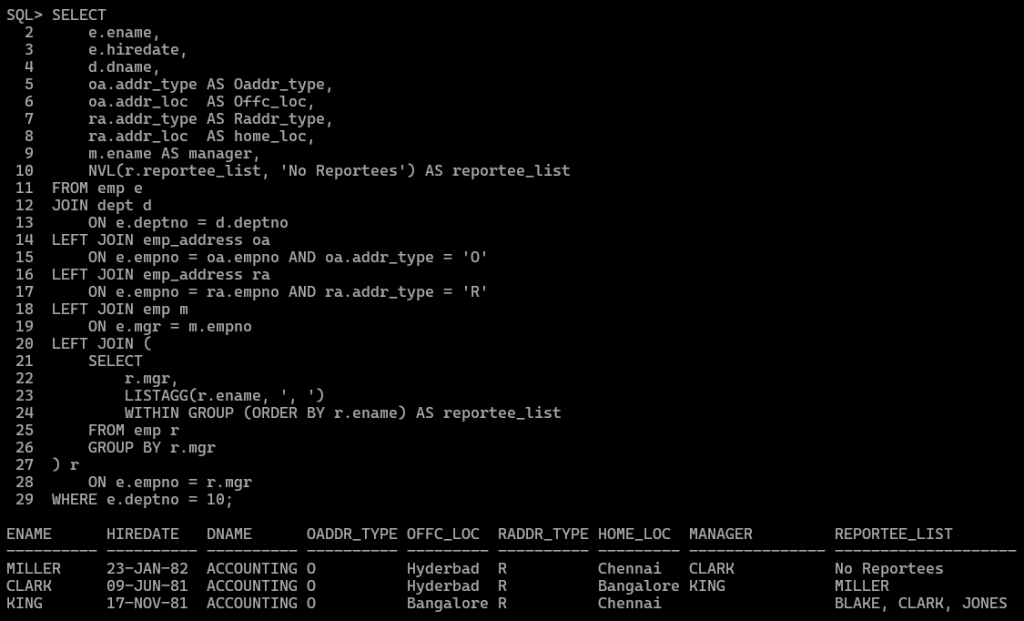
どちらのアプローチでも次のものが必要です。
- 理解するには高度なSQLの専門知識が必要
- 複雑な結合条件とエイリアスは維持が難しい
- 関係が深まるにつれて、維持することが難しくなります。
- 報告先を取得するための集約サブクエリ(LISTAGG)
ネイティブGraphQLアプローチ – クリーンで直感的
ここで、 Oracle Database 26ai内で直接実行されるネイティブ GraphQL を使用して同じロジックを表現してみましょう。
select json_serialize(data pretty) as GraphQL_JSON from graphql(' emp @where (sql : " deptno = 10 ") { ename, hiredate, deptName :dept{dname}, emp @unnest @link( from: ["MGR"], to: ["EMPNO"] ) {ManagerName : ename}, reportee_list :emp @link( from: ["EMPNO"] , to: ["MGR"] ) [{ReporteeName : ename}], empAddressDetails : emp_address {addr_type, addr_loc}}' );
注記:
@where - より大きなデータセットから特定の情報をフィルタリングします
@unnest - 中間オブジェクトをフラット化します
@link - テーブルを結合またはリンクするときに使用する外部キーを定義します
GraphQLディレクティブの詳細については、こちらを参照してください。

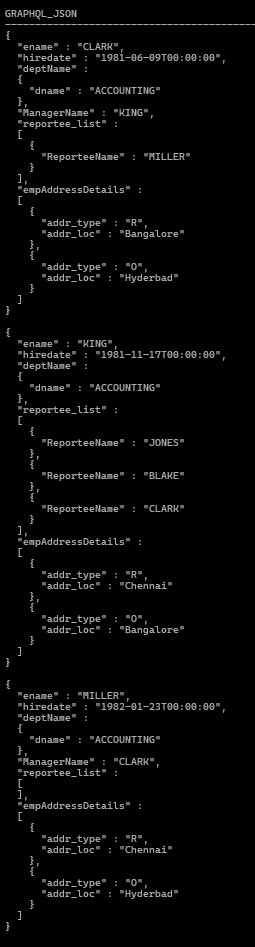
addr_loc で order したい場合は、以下のように@orderby の説明を追加します。
select json_serialize(data pretty) as GraphQL_JSON from graphql(' emp @where (sql : " deptno = 10 ") { ename, hiredate, deptName :dept{dname}, emp @unnest @link( from: ["MGR"], to: ["EMPNO"] ) {ManagerName : ename}, reportee_list :emp @link( from: ["EMPNO"] , to: ["MGR"] ) [{ReporteeName : ename}], empAddressDetails : emp_address @orderby (sql:" addr_loc desc") {addr_type, addr_loc}}' );
このGraphQLクエリが強力な理由
この単一の GraphQL クエリは以下を置き換えます:
- 複数の結合
- 相関サブクエリ
- 集計ロジック
- アプリケーション側のデータシェーピング
主な観察事項
- 自己参照関係は自然です。
マネージャーと報告先の関係は、自己結合の複雑さなしに、@link を使用して宣言的に表現されます。 - 階層型データは最高です。
従業員、管理者、報告先、部門、住所はすべて、ネストされたオブジェクトとして自然にモデル化されます。 - 開発者に SQL 結合ロジックが公開されていないため、開発者はテーブルを結合する方法ではなく、必要なデータに集中できます。
- API 対応の JSON 出力
結果は構造化された JSON として返されます。フロントエンド アプリケーション、マイクロサービス、GraphQL クライアントに最適です。
重要なポイント
クエリが複雑になるにつれて、SQLの複雑さは指数関数的に増大します。特に自己結合や集計では顕著です。Oracle AI Database 26aiのネイティブGraphQLを
使用すると、同じロジックを単一の読みやすい宣言型クエリで表現できます。
このアプローチ:
- 読みやすさが劇的に向上
- 開発と保守の労力を削減
- データベースアクセスを最新のAPI設計原則に適合させる
このシリーズの次の部分では、ORDS / API呼び出しを使用して上記のGraphQLクエリを呼び出す方法を示します。



コメント
コメントを投稿