x86 + Arm + GPU異機種間コンピューティングを混在させたNextflowをOCIで実行 (2026/02/10)
x86 + Arm + GPU異機種間コンピューティングを混在させたNextflowをOCIで実行 (2026/02/10)
https://blogs.oracle.com/cloud-infrastructure/run-nextflow-with-heterogeneous-computing-on-oci
投稿者:Leo Li | AI Infrastructure Architect
Nextflowをクラウドで実行すると、俊敏性と結果までの時間が向上しますが、インスタンスの選択が最適ではないこと、スケジュールの調整、そしてキャパシティがステージの需要に追いつかない場合の無駄な支出によって、コストと完了時間が依然として大きく左右される可能性があります。OCIは、動的なリソースプロビジョニング、透明性の高い従量課金制、そして一貫したパフォーマンスによってこの問題に対処します。以前の本番環境レベルのnf-core/methylseq調査では、OCIは他のクラウドの動的バッチサービスと比較して、バッチコンピューティングコストを最大70%削減しました( 「OCIでNextflowのコストを70%削減」を参照)。
GPUアクセラレーションとArm CPUコンピューティングが利用可能になったことで、最適化をさらに推し進めることができます。GPUはアクセラレーションの恩恵を受けるステージを短縮し、Arm CPUのキャパシティは互換性のあるワークロードのCPUコストをさらに削減できます。この記事では、OCI上の単一のNextflowパイプラインでx86 CPU、Arm CPU、GPUを組み合わせ、各ステージが最適なインフラストラクチャで実行され、キャパシティがアイドル状態になるのではなく、需要に応じて変化する仕組みを紹介します。
この投稿では、次のことについて説明します。
- OCI が Nextflow のステージごとに異種コンピューティングを可能にする方法を示します。デモ パイプラインのラベルベース ルーティングを介して、x86 CPU、Arm CPU、および GPU の容量を単一のパイプラインで混在させます。
- パイプラインのリソース フットプリント (タスク数、要求された CPU/メモリ/GPU、Nextflow トレース/タイムライン レポート) を使用して、ワークロードの動的な性質を明示的にし、それをコストと結果までの時間に結び付けます。
- OCI のファーストクラスの IaC サポートにより、顧客がインフラストラクチャをソフトウェアとして扱うことができる方法を示します。つまり、OCI リソースをコードとして定義、バージョン管理、自動化し、大規模な実行を繰り返し可能にします。
背景: 異機種混在の Nextflow パイプラインと OCI インフラストラクチャ
Nextflowは、ゲノミクス、バイオインフォマティクス、データ集約型AIで広く使用されているワークフローエンジンです。単一のプロダクションパイプラインには、コンピューティングプロファイルが大きく異なる複数のステージが混在することがよくありますが、その異種性をOCI上で運用可能にすることが現実的になりました。
- 成熟したツールチェーンとコンテナ全体で幅広いソフトウェア互換性と「デフォルト パス」パフォーマンスを実現するx86 CPU 。
- 加速によってウォールクロック時間が短縮される並列化可能なステージ用のGPU (特定のアライメント、ディープ ラーニング、高速分析ステップなど)。
- コスト効率の高いスループットと高いコア数を実現するArm CPU 。コンテナーと依存関係が Arm をサポートしている場合、高度にスレッド化された CPU 依存のステージには魅力的です。
実際のパイプラインでは、リソース需要も時間とともに変化します。アクセラレーションが最も重要となる、長く時間のかかるステージ(例えばアライメント)が続き、その後に短いファンアウト処理が集中的に発生し、その後にCPUが制限要因とならないメモリやI/Oにバインドされたステージが続くといった状況が見られます。
OCIは、各ステージを最適なコンピューティング(x86、Arm、GPU)にマッピングし、一貫したインフラストラクチャパフォーマンスと透明性のある従量課金制を実現できるため、このパターンに最適です。目標は、需要に応じてキャパシティを調整し、コストと成果までの時間の両方を最適化できる、プログラム可能でステージ対応の実行モデルです。
OCIの技術アーキテクチャ
このブログでは、Infrastructure as Code (IaC) 実行モデルを使用して異種コンピューティングを実用化します。各 Nextflow ステージは最適な OCI コンピューティング (x86 CPU、Arm CPU、または GPU) にルーティングされ、タスクの有効期間中オンデマンドでプロビジョニングされ、OCI オブジェクト ストレージが作業ディレクトリと成果物の耐久性のあるバックエンドとして使用されます。
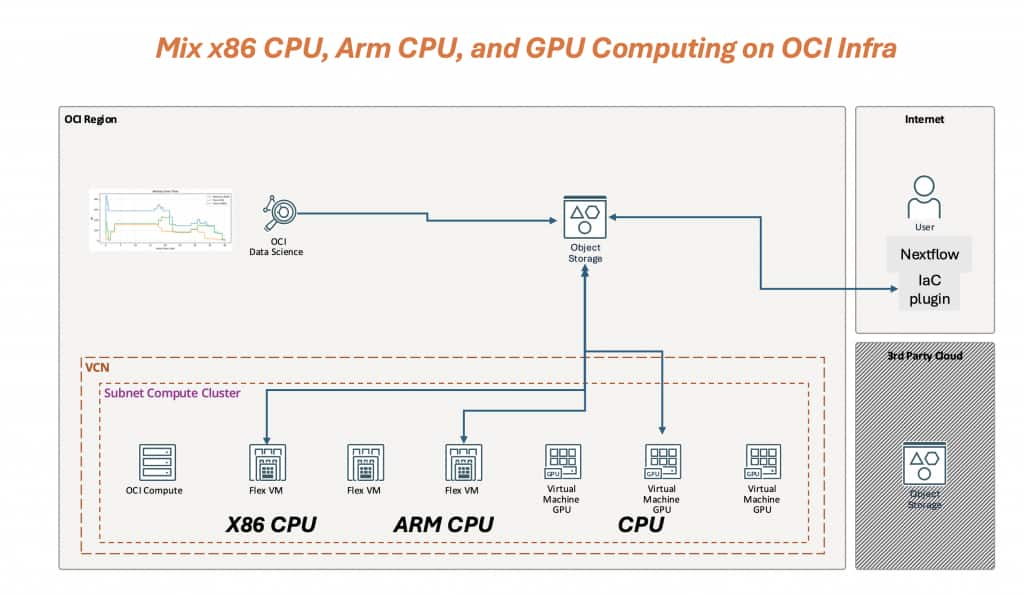
図 1 – OCI 上での x86 CPU、Arm CPU、GPU コンピューティングの混在: Nextflow IaC エグゼキューターは VCN/サブネット内でステージごとの OCI コンピューティングをプロビジョニングし、OCI オブジェクト ストレージはすべてのステージで共有される耐久性のある作業/成果物レイヤーを提供します。
図 1 には 3 つの重要な考え方が示されています。
- 動的: 容量はパイプラインのタイムラインに従います。CPU ステージは x86 または Arm Flex VM に配置され、GPU 容量は GPU ステージの実行時にのみ表示されます。
- プログラム可能 (IaC) : プロセス ラベルから OCI シェイプ/イメージ/ネットワーク/ストレージへのマッピングは、コードとして定義され、バージョン管理され、自動化されています。
- 異種ネイティブ: x86 CPU、Arm CPU、GPU は、パイプラインを個別の実行に分割することなく、同じワークフローのさまざまなステージに最適なオプションです。
設定/方法
1) ラベルルーティングでArm + GPUを有効にする(config)
OCIで異種コンピューティングを構成するには、Nextflowセレクター(通常はwithLabel(オプションでwithNameも))を使用してステージをルーティングし、ステージごとにOCIの シェイプ と イメージをピン留めします 。以下の設定では、
- armcpu ステージは、ext.shape + ext.image を指定して Arm 上で実行されます。
- GPU ステージは GPU シェイプと GPU 割り当てを要求します。
process { executor = 'iac' withLabel: gpu { cpus = 15 memory = '240 GB' accelerator = [ type: 'VM.GPU.A10.1', request: 1 ] containerOptions = '--gpus all' } withLabel: armcpu { cpus = 4 memory = '8 GB' ext.shape = '1 VM.Standard.A1.Flex' ext.image = 'ocid1.image.oc1.ap-singapore-1.aaaaaaaasnihixxx' } }
実際には、x86 CPU ステージは IaC 設定のデフォルト (defaultShape や image など) を継承しますが、Arm ステージと GPU ステージは必要なものをオーバーライドします。
2) デモパイプライン: x86 FASTP → 20x Arm CPU_FANOUT_STAGE → GPU GPU_STAGE
以下のデモ パイプラインは意図的に小さくなっていますが、異種フローの全体を一目で確認できます。
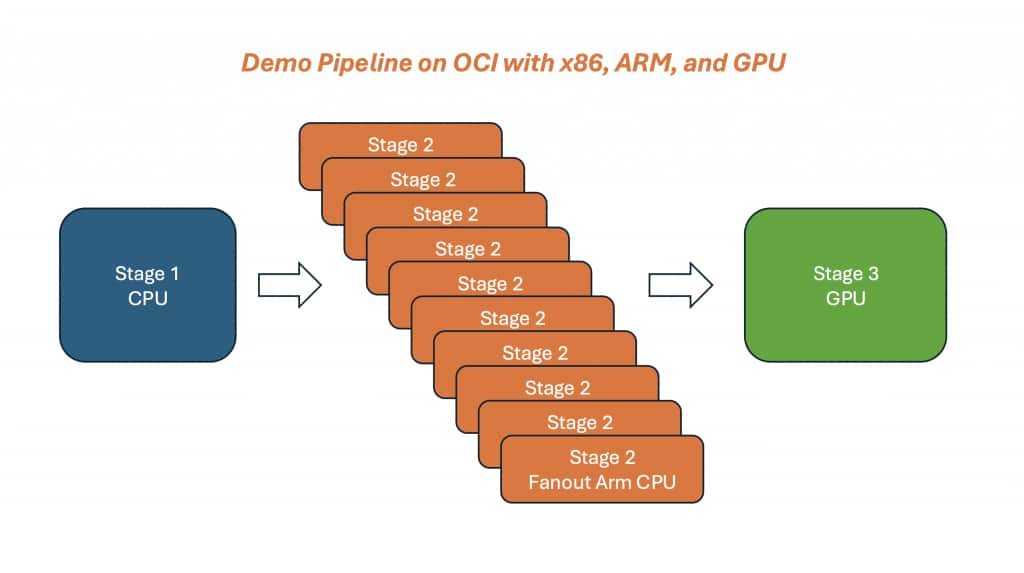
図2 – x86 CPU(QC)、Arm CPUファンアウト(20タスク)、GPU統合ステージ(2バッチ)を混在させた単一のNextflow実行。ステージルーティングはラベルによって制御されます。
- FASTP はラベル「cpu」を使用します (一般的なバイオインフォマティクス コンテナーとの互換性のため、デフォルトでは x86)。
- CPU_FANOUT_STAGE はラベル 'armcpu' を使用し、 20 個の 短いタスクにファンアウトして、バースト的なスレッド スループット作業をエミュレートします。
- GPU_STAGE はラベル「gpu」を使用し、ファンアウト出力を 2 つの GPU バッチに統合します。
重要なポイントは、ステージの配置がラベルによって決まることです。互換性には x86、コスト効率の高いスループットには Arm、そして加速が効果的な場合は GPU のみとなります。
結果と数字
このデモ実行は小規模ですが、OCI で重要となる 2 つの動作 ( ステージごとの異種コンピューティング と、 パイプラインのタイムラインに従う動的な IaC 駆動型プロビジョニング)がすでに示されています。
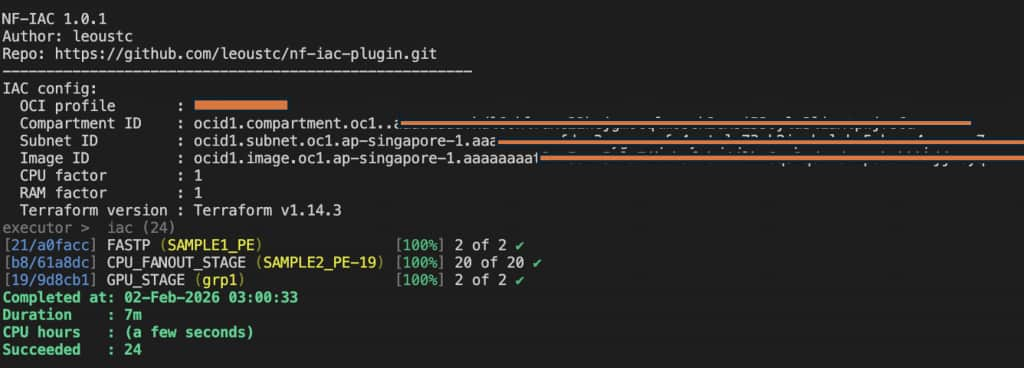
図3 – IaCエグゼキューターを使用したNextflowの実行は正常に完了しました。x86 QCタスク、Armファンアウトバースト、そして2つのGPUタスクが含まれています。これが、私たちが目指す「単一パイプライン、混合インフラストラクチャ」の結果です。

図4 – OCIコンソールで確認できる、1回の実行における異種コンピューティングのエビデンス:x86 CPUステージ、Arm CPUワーカーのバースト、そしてアクセラレーションステージに合わせてサイズ設定されたGPUワーカー。インスタンスはステージの完了に合わせて生成され、終了します(IaC駆動型ライフサイクル)。
実行テレメトリから、要求されたリソースが時間の経過とともにどのように変化するかを視覚化することもできます(1分間隔)。以下のグラフは意図的に階段状になっています。各「ステップ」は、異なるコンピューティングプロファイルを使用するステージに対応しています。
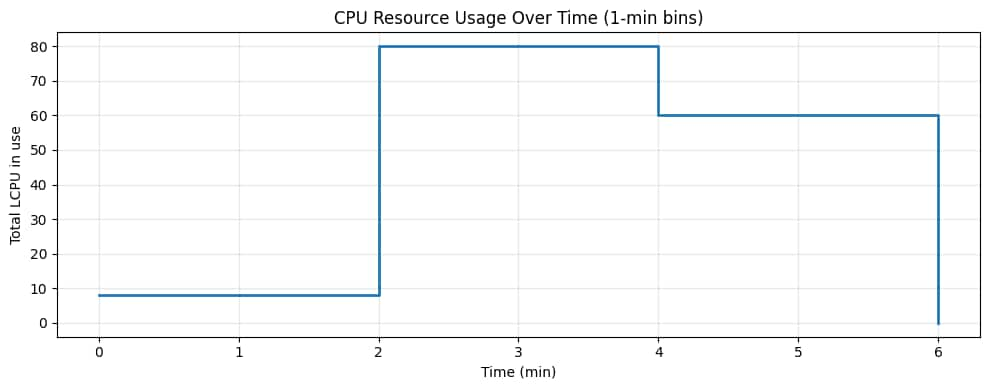
図5 – CPUの経時変化。ベースラインのx86 QCステージは小さく、Armファンアウトステージでは多くの並列タスクによってCPUが急増し、GPUステージでは高速化された作業を実行するためにCPU割り当ては少ないものの、より大きなCPU割り当てを消費します。
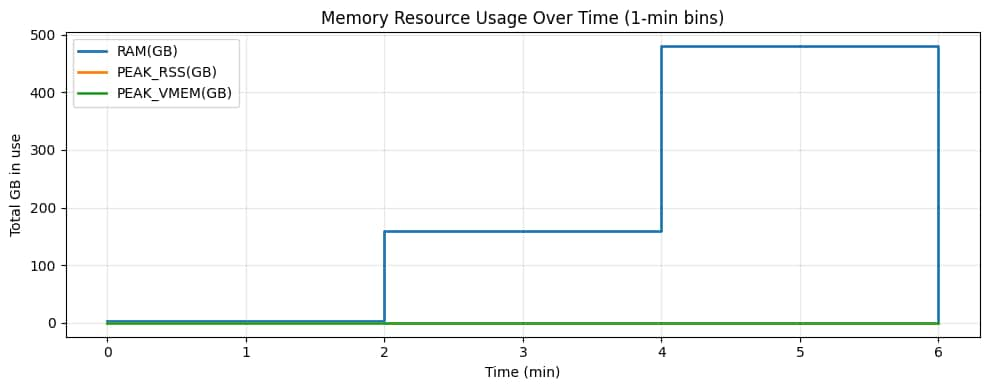
図6 – メモリの経時変化。Armファンアウトフェーズでは総メモリ量が増加し(多数の小さなワーカー)、その後GPUフェーズではメモリ使用量が上昇します(より少ない、より大きなGPUワーカー)。
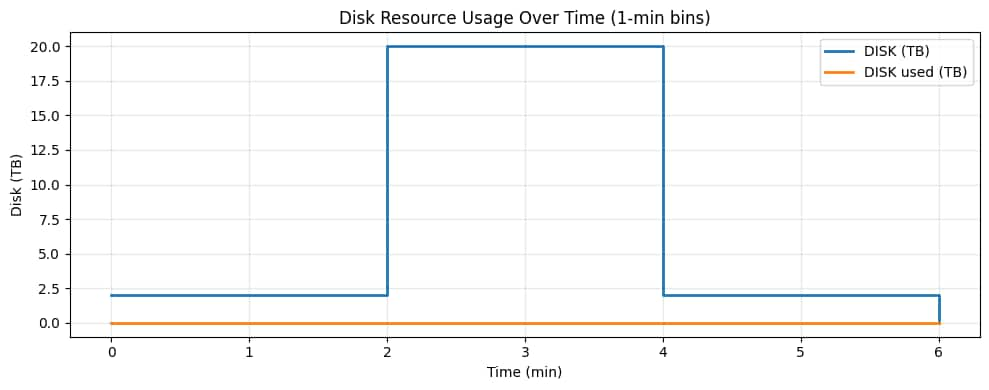
図7 – ディスクの経時変化。ディスクはワーカーVMごとに割り当てられるため、実際に書き込まれるデータ量が少なくても、ファンアウトバーストによって割り当てディスク容量が増加します。これは「Dynamic Infrastructure as Code」のシグナルであり、ストレージとコンピューティング容量はステージに応じて拡張され、ステージが完了すると解放されます。
まとめ
このPoCは、OCIインフラストラクチャが、x86 CPU、Arm CPU、GPUステージを混在させた真にヘテロジニアスなコンピューティング環境を備えた単一のNextflowパイプラインを実行し、ワークフローの進行に合わせて適切なリソースを動的にプロビジョニングできることを実証しています(図3~7)。実行全体を通して単一の「ベストエフォート」クラスタ形状を強制するのではなく、各ステージは最適なコンピューティングプロファイルに配置され、キャパシティは自動的に作成および解放されます。
3つのポイント:
- ネイティブな異種コンピューティング: Nextflow ステージでは、互換性のために x86、コスト効率の高いスループットのために Arm、加速ステージのために GPU を 1 回の連続実行でターゲットにすることができます。
- 柔軟性のための Infrastructure as Code : ステージごとに図形や画像を固定し、構成をバージョン管理し、実行を繰り返し可能にするなど、顧客は計画どおりに OCI をプログラムできます。
- コストと完了時間を最適化: 混合パイプラインを使用すると、常時オンの GPU を回避することで無駄を削減できるほか、緊急ステージで GPU アクセラレーションのメリットを享受することで結果までの時間を短縮できます。



コメント
コメントを投稿