OCI PostgreSQLデータ同期: 初期ロード(ダンプ/リストア)およびCDCとpglogical (2026/03/12)
OCI PostgreSQLデータ同期: 初期ロード(ダンプ/リストア)およびCDCとpglogical (2026/03/12)
https://blogs.oracle.com/cloud-infrastructure/oci-psql-sync-init-load-dump-restore-cdc-pglogical
投稿者:Kaviya Selvaraj
1.1. はじめに
組織は、アプリケーションの稼働時間を確保し、環境間でデータの一貫性を維持するために、シームレスなデータ移行とリアルタイムレプリケーションへの依存度を高めています。堅牢な論理レプリケーション拡張機能を備えたOCI PostgreSQLは、大量データ転送と変更データキャプチャ(CDC)の両方に対応する柔軟なソリューションを提供します。
pg_dumpおよびpg_restoreをpglogical (またはネイティブ論理レプリケーション)と組み合せて利用すると、OCI PostgreSQLデータベースで停止時間がほぼゼロの移行と効率的なCDCが可能になります。pg_dump/pg_restoreは、最初のフル・データ・ロードを管理し、pglogicalは、このプロセス中およびプロセス後に進行中の変更を取得します。
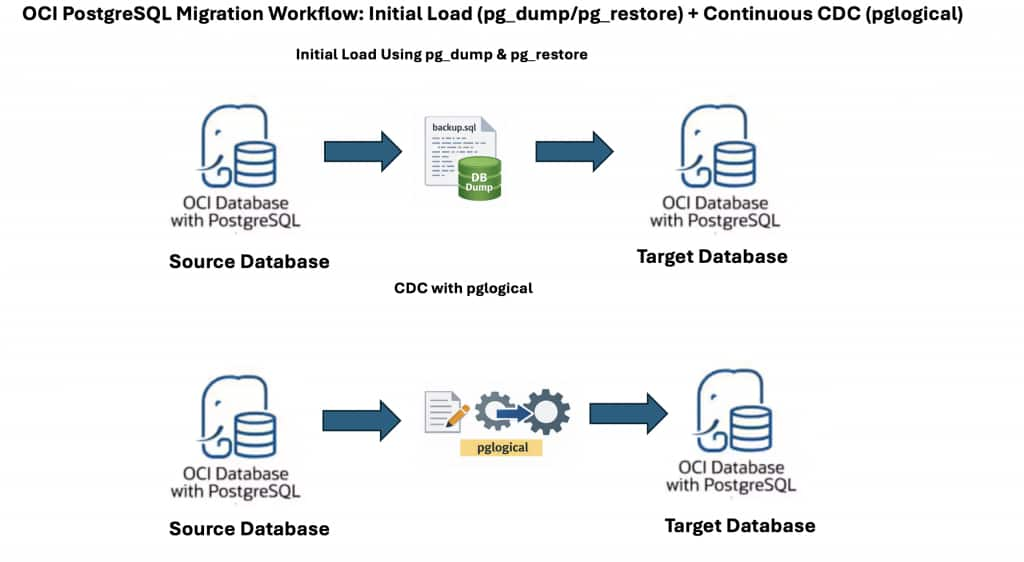
このガイドでは、信頼性の高いアプローチについて説明します。まず、初期データ移行にはpg_dumpとpg_restoreを使用し、その後、継続的な増分レプリケーションのためにpglogicalを設定します。この方法により、ダウンタイムを最小限に抑え、ソース OCI PostgreSQL データベースとターゲット OCI PostgreSQL データベース間のデータの一貫性を確実に維持できます。
このチュートリアルでは OCI PostgreSQL に焦点を当てていますが、ネットワークの到達可能性、適切な権限、必要な拡張機能のサポートなどの前提条件が満たされている限り、他のクラウド プロバイダーまたはオンプレミスで実行されている PostgreSQL でも同じパターンが機能します。
1.2. ステップ1:初期データロード – ソースデータベースからのエクスポート
信頼性の高いレプリケーション設定は、一貫性のある完全なデータスナップショットから始まります。最初のステップは、ソースOCI PostgreSQLデータベースからグローバルオブジェクト、データベーススキーマ、そして実際のデータをエクスポートすることです。
1.2.1. グローバルオブジェクト(ロールなど)のエクスポート
テーブルスペース情報を含めずにアクセス制御を保持するために、ユーザー、グループ、および権限をエクスポートします。
pg_dumpall -U psql -h <source_ip_address> -g --no-role-passwords --no-tablespaces -f global_role_object.sql</source_ip_address>1.2.2. データベーススキーマのエクスポート
スキーマのみのダンプを生成します。これには構造(テーブル、インデックス)は含まれますが、データは含まれません。
pg_dump -U psql -h <source_ip_address> -s -C -E 'UTF8' -d <database_name> -f schema_dump.sql</database_name></source_ip_address>1.2.3. テーブルデータのエクスポート
スキーマの詳細を除き、テーブルデータをすべて抽出します。
pg_dump -U psql -h <source_ip_address> -a -E 'UTF8' -d <database_name> -f data_dump.sql</database_name></source_ip_address>1.3. ステップ2:初期データロード – ターゲットデータベースへのインポート
データのエクスポートが完了したら、次の段階はデータをターゲットサーバーに復元することです。
1.3.1. グローバルオブジェクトのインポート
ユーザーアカウント、グループ、および関連する権限を再作成します。
psql -U psql -d postgres -h <target_ip_address> -f global_role_object.sql</target_ip_address>注記:
1.3.2. データベーススキーマのインポート
対象システム上にデータベース構造を作成します。
psql -U psql -d postgres -h <target_ip_address> -f schema_dump.sql</target_ip_address>注:先に進む前に、権限の不一致やオブジェクトの不一致に関するエラーをすべて修正してください。
1.3.3. テーブルデータのインポート
エクスポートされたデータをターゲット テーブルに入力します。
psql -U psql -d postgres -h <target_ip_address> -f data_dump.sql</target_ip_address>詳細については、pg_dumpおよびpg_restoreを使用したデータの移行 に関する公式 OCI ドキュメントを参照してください。
1.4. ステップ3:変更データキャプチャ(CDC)用にpglogicalを設定する
両環境が同期されたら、pglogicalを使用して、進行中の変更をソースからターゲットへリアルタイムで複製します。これにより、データの完全ロードを繰り返すことなく、スムーズな増分更新が可能になります。
1.4.1. ソースデータベース – プロバイダとして設定する
1.4.1.1. プロバイダノードを作成する
ソースデータベースを論理レプリケーションプロバイダとして確立します。
SELECT pglogical.create_node( node_name := 'provider1', dsn := 'host=source_fqdn port=5432 user=psql password=xxxx dbname=postgres' );
1.4.1.2. レプリケーションセットの作成
複製する変更の種類(挿入、更新、削除、切り捨て)を指定します。
SELECT pglogical.create_replication_set( 'default1', replicate_insert := true, replicate_update := true, replicate_delete := true, replicate_truncate := true );
1.4.1.3. すべてのテーブルをレプリケーションセットに追加する
パブリックスキーマのすべてのテーブルをレプリケーションセットに含める。
SELECT pglogical.replication_set_add_all_tables('default1',ARRAY['public']);1.4.2. 対象データベース – サブスクライバーとして設定する
データ損失なくCDCを確立するには、レプリケーション開始点をダンプスナップショットと同期させる必要があります。
1.4.2.1. サブスクライバーノードの作成
ターゲットを論理レプリケーションノードとして構成します。
a. サブスクライバーノードの作成:
ターゲットを論理レプリケーションノードとして定義します。
SELECT pglogical.create_node( node_name := 'subscriber1', dsn := 'host=target_fqdn port=5432 user=psql password=xxx dbname=postgres' );b. サブスクリプションの作成:初期データコピーなしで
サブスクリプションを作成します。プロバイダーノードからの変更を購読します。
SELECT pglogical.create_subscription( subscription_name := 'subscription1', provider_dsn := 'host=source_fqdn port=5432 user=psql password=xxx dbname=postgres', replication_sets := ARRAY['default'], synchronize_data := false );この時点で、CDC が流れ始めます。
1.4.3. サブスクリプションのステータスを確認する:
以下のコマンドを使用して、購読状況を確認してください。
SELECT * FROM pglogical.show_subscription_status();ステータスにサブスクリプションが表示されるはずですreplicating。
1.5.重要な考慮事項:
次のセクションでは、CDCpg_dump for initial loadと組み合わせて使用する際の重要な考慮事項について説明します。pglogical
1.6. 結論
要約すると、OCI PostgreSQLのネイティブツールを初期データロードに活用しpg_dump、pg_restorepglogicalのリアルタイム変更データキャプチャ(CDC)機能を組み合わせることで、データベースの移行と同期のための堅牢かつ柔軟なソリューションが実現します。このアプローチにより、ターゲット環境は一貫性のあるデータセットから開始し、ソースからの継続的な変更にシームレスに対応して最新の状態を維持できます。
このガイドに記載されている詳細な手順に従うことで、チームはダウンタイムを最小限に抑え、データ損失のリスクを軽減し、高可用性とデータ統合の両方のユースケースに対応できる信頼性の高い基盤を構築できます。いつものように、本番環境に展開する前に、管理された環境でこれらの手順をテストし、組織のセキュリティおよびコンプライアンス要件に合わせて構成を調整することが不可欠です。
追加リソース



コメント
コメントを投稿