Oracle BI Publisherデータ・モデルからデータ抽出へ (2026/06/29)
Oracle BI Publisherデータ・モデルからデータ抽出へ (2026/06/29)
https://www.ateam-oracle.com/from-oracle-bi-publisher-data-models-to-data-extracts
投稿者:Elói Lopes | Cloud Solution Architect
はじめに
Oracle BI Publisherのデータモデルは、最も重要な実装の詳細であるSQLを隠していることがよくあります。このプロジェクトでは、ソースアーティファクトはBI Publisherの`.xdm.catalog`ファイルです。目標は、埋め込まれたSQLを抽出し、データ抽出定義に変換することです。
このプロセスは、以下の3つの段階でそれを実行します。
1. BI PublisherのデータモデルからSQLクエリを抽出します。
2. 選択したSQLクエリをOracle AI Agent Studioに送信し、抽出クエリJSONに変換します。
3. 生成されたペイロードを使用して、バッチ API を介してデータ抽出を作成して実行します。
その結果、BIPデータモデルのSQLからAPIで作成されたデータエクスポート定義への実用的な橋渡しが実現しました。
ワークフロー
プロジェクトのワークフローは、圧縮された BI Publisher カタログファイルから始まり、データと SaaS バッチ API の応答成果物がディスクに書き込まれることで終了します。
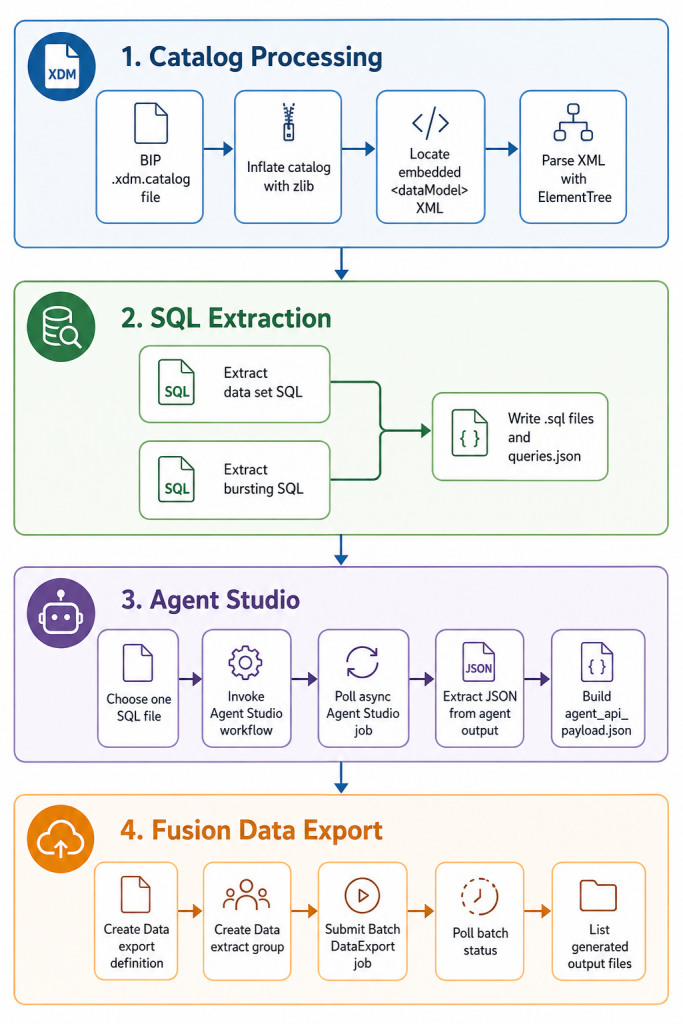
重要:現在、抽出ビューにマッピングされているテーブルはごく一部です。サポートされていないテーブルについては、エージェントはSQL変換を提供できません。前提条件として、お客様はまず、変換対象のテーブルがサポートされていることを確認してください。
ステップ1:BIPカタログからSQLを抽出する
最初のスクリプトは`scripts/extract_bip_xdm_queries.py`です。このスクリプトはカタログファイルをバイト列として読み込み、解凍し、埋め込まれた`<dataModel>` XMLを見つけ、通常のデータセットとバースト定義からSQLノードを解析します。
出力ディレクトリを指定して実行してください。
python3 scripts/extract_bip_xdm_queries.py \
bip.xdm.catalog \
--out-dir extractedコアとなる解凍ステップは小さい。
def inflate_catalog(catalog_path):
return zlib.decompress(Path(catalog_path).read_bytes()).decode(
"utf-8",
errors="replace",
)インフレーション後、スクリプトはペイロード内から直接データモデルのXMLを見つけます。
def extract_data_model_xml(inflated_text):
start = inflated_text.find("<dataModel")
if start == -1:
raise ValueError("Could not find a <dataModel> element in the inflated catalog payload.")
end_tag = "</dataModel>"
end = inflated_text.find(end_tag, start)
if end == -1:
raise ValueError("Found <dataModel>, but could not find the closing </dataModel> tag.")
return inflated_text[start : end + len(end_tag)]XMLが解析されると、`<dataSets>/<dataSet>/<sql>`からトップレベルのデータセットSQLが収集されます。
def top_level_data_sets(root):
data_sets = child_named(root, "dataSets")
if data_sets is None:
return []
queries = []
for data_set in children_named(data_sets, "dataSet"):
sql = child_named(data_set, "sql")
if sql is None:
continue
queries.append(
{
"kind": "dataSet",
"name": data_set.attrib.get("name", "unnamed_data_set"),
"dataSourceRef": sql.attrib.get("dataSourceRef"),
"sql": extract_sql(sql),
}
)
return queriesバーストクエリは、`<bursting>/<burst>/<dataSet>/<sql>` の下に存在するため、個別に抽出されます。
def bursting_data_sets(root):
bursting = child_named(root, "bursting")
if bursting is None:
return []
queries = []
for burst in children_named(bursting, "burst"):
burst_name = burst.attrib.get("name")
for index, data_set in enumerate(children_named(burst, "dataSet"), start=1):
sql = child_named(data_set, "sql")
if sql is None:
continue
fallback_name = f"{burst_name or 'burst'}_{index}"
queries.append(
{
"kind": "bursting",
"name": data_set.attrib.get("name", fallback_name),
"burstName": burst_name,
"dataSourceRef": sql.attrib.get("dataSourceRef"),
"sql": extract_sql(sql),
}
)
return queries付属のサンプルでは、スクリプトは4つのSQLファイルを作成します。
extracted/
data_model.xml
queries.json
extracted_sql1.sql
extracted_sql2.sqlqueries.json のマニフェストには、クエリの種類、名前、データソースの参照、および生成された SQL ファイル名が記録されます。
ステップ2:Oracle AI Agent Studioを使用してSQLを変換する
抽出後、`scripts/call_agent_studio.py` は 1 つの SQL ファイルを Oracle AI Agent Studio ワークフローに送信します。
次のように実行してください。
python3 scripts/call_agent_studio.py \
--sql-file extracted/extracted_sql1.sql \
--out-dir extracted/agent_studio/extracted_sql1SQLファイルが指定されると、スクリプトは固定の指示を先頭に追加し、エージェントが下流のAPIに必要なJSONオブジェクトのみを返すようにします。
AGENT_OUTPUT_INSTRUCTIONS = """\
Convert the following SQL into the extraction query JSON format.
Return only the final BQL representation (viewQueries/select/namedSelect).
Do not include markdown, explanations, comments, or any text outside the JSON object.
Keep the output concise.
"""スクリプトは次に、非同期エージェントスタジオエンドポイントを呼び出します。
def invoke_agent(args, token, message):
url = (
f"{args.agent_base_url.rstrip('/')}/api/fusion-ai/orchestrator/agent/v2/"
f"{urllib.parse.quote(args.workflow_code)}/invokeAsync"
)
payload = {
"conversational": True,
"version": args.version,
"status": args.status,
"message": message,
}
return request_json(
url,
method="POST",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {token}",
},
data=json.dumps(payload).encode("utf-8"),
)このジョブは非同期であるため、スクリプトはステータスがCOMPLETEになるまでポーリングを繰り返します。
def poll_agent(args, token, job_id):
url = (
f"{args.agent_base_url.rstrip('/')}/api/fusion-ai/orchestrator/agent/v2/"
f"{urllib.parse.quote(args.workflow_code)}/status/{urllib.parse.quote(job_id)}"
)
while time.monotonic() <= deadline:
last_response = request_json(
url,
method="GET",
headers={"Authorization": f"Bearer {token}"},
)
status = last_response.get("status") or "UNKNOWN"
if status == "COMPLETE":
return last_response
time.sleep(args.poll_interval)
出力フィールドにはテキスト内に埋め込まれたJSONが含まれる可能性があるため、スクリプトは最初に見つかった有効なJSONオブジェクトまたは配列をスキャンします。
def extract_first_json(value):
decoder = json.JSONDecoder()
text = str(value)
for index, char in enumerate(text):
if char not in "{[":
continue
try:
parsed, _ = decoder.raw_decode(text[index:])
return parsed
except json.JSONDecodeError:
continue
raise ValueError("Could not find a JSON object or array in the agent output.")最後に、抽出されたJSONは、データツールAPIが想定する形式にラップされます。
def build_Data_artifacts_payload(agent_output):
extraction_query = extract_first_json(agent_output)
if not isinstance(extraction_query, dict):
raise ValueError("Agent output must contain a JSON object for extractionQuery.")
return {
"DataArtifacts": {
"extractionQuery": json.dumps(extraction_query, separators=(",", ":")),
}
}`–out-dir` を使用すると、このステージは以下を書き込みます。
agent_invoke_response.json
agent_status_response.json
agent_output.json
agent_api_payload.json次の段階で最も重要なファイルはagent_api_payload.jsonです。
ステップ3:データ抽出を作成して実行する
最後のスクリプトである scripts/call_Data_extract_api.py は、extracted/agent_api_payload.json を読み込み、それを使用してデータエクスポート定義を作成します。
プロジェクトのルートディレクトリから実行してください。
python3 scripts/call_Data_extract_api.pyスクリプトは、生成されたエージェントスタジオのペイロードを読み込むことから始まります。
def load_agent_api_payload(path):
payload = json.loads(Path(path).read_text(encoding="utf-8"))
Data_artifacts = payload.get("DataArtifacts")
if not isinstance(Data_artifacts, dict):
raise ValueError("agent_api_payload.json must contain a DataArtifacts object.")
extraction_query = Data_artifacts.get("extractionQuery")
if not isinstance(extraction_query, str) or not extraction_query.strip():
raise ValueError(
"agent_api_payload.json must contain DataArtifacts.extractionQuery "
"as a non-empty string."
)
return Data_artifacts次に、エクスポート定義ペイロードを構築します。
def build_create_extract_payload(extract_name, Data_artifacts):
return {
"name": extract_name,
"description": EXTRACT_DESCRIPTION,
"owner": OWNER,
"ownerRole": OWNER_ROLE,
"exportConfiguration": {
"type": "BV",
"outputDataFormat": OUTPUT_DATA_FORMAT,
"csvDelimiter": CSV_DELIMITER,
"sortBy": None,
"csvFormat": None,
"historyStartDate": None,
},
"DataArtifacts": Data_artifacts,
}次に、新しく作成された抽出を指す抽出グループを作成します。
def build_create_group_payload(extract_name, extract_group):
return {
"name": extract_group,
"owner": OWNER,
"ownerRole": OWNER_ROLE,
"groupedExtracts": {
"items": [
{
"name": extract_name,
}
]
},
}次に、データ「DataExport」ジョブ定義に対してSaaSバッチジョブを送信します。
def build_batch_payload(extract_name):
schedule_name = f"{extract_name}Schedule"
return {
"serviceName": "Data",
"jobDefinitionName": "DataExport",
"description": f"{schedule_name}::{extract_name}::{BATCH_EXTRACT_TYPE}::{BATCH_RECURRENCE}",
"requestParameters": {
"submit.argument1": extract_name,
"submit.argument2": BATCH_SUBMIT_ARGUMENT2,
},
}バッチジョブは、成功または失敗の状態に達するまでポーリングされます。
def poll_batch(batch_token, job_request_id):
while time.monotonic() <= deadline:
last_response = api_request(
"GET",
f"/api/saas-batch/jobscheduler/v1/jobRequests/{urllib.parse.quote(job_request_id)}",
batch_token,
)
body = last_response["body"]
status = (
body.get("jobStatus")
or body.get("jobDetails", {}).get("jobStatus")
or body.get("jobProgress", {}).get("status")
or "UNKNOWN"
)
if status in BATCH_FAILURE_STATES:
raise RuntimeError(f"Batch job {job_request_id} ended with status {status}")
if status in BATCH_SUCCESS_STATES:
return last_response
time.sleep(POLL_INTERVAL_SECONDS)ジョブが成功した場合、スクリプトは出力ファイルを一覧表示します。
output_files_response = api_request(
"GET",
f"/api/saas-batch/jobfilemanager/v1/jobRequests/{urllib.parse.quote(job_request_id)}/outputFiles",
batch_token,
)
output_files = output_files_response["body"].get("items", [])この段階では、データとバッチリクエストおよびレスポンスの成果物が`extracted/Data`ディレクトリに書き込まれます。
まとめ
このプロジェクトでは、検査が困難な BI Publisher の .xdm.catalog アーティファクトを、再現可能な抽出および変換ワークフローに変換します。エクストラクタは隠された SQL を可視化し、Agent Studio はその SQL を Data が想定する抽出クエリ JSON に変換します。そして、最終スクリプトは Batch を介して Data のエクスポートを作成および実行します。



コメント
コメントを投稿