Oracle Data Science Agent: Autonomous AI Databaseにおける会話型機械学習 (2026/06/23)
Oracle Data Science Agent: Autonomous AI Databaseにおける会話型機械学習 (2026/06/23)
投稿者:Mark Hornick | Senior Director, AI and Machine Learning Product Management
Oracle Data Science AgentがOracle Autonomous AI Database Serverless 26ai向けに一般提供開始となり、データベース内で直接、最新の対話型エクスペリエンスによる分析と機械学習を実現します。
Data Science Agent を使用すると、Oracle Machine Learning のガイド付きチャットを通じて、データのプロファイリング、特徴量の準備、モデルのトレーニング、結果の評価、推論 SQL の生成を行うことができます。処理はデータベース内で実行されるため、データが既に存在する場所で機械学習ワークフローを構築でき、データ移動の削減、ガバナンスの簡素化、インサイト獲得までの時間の短縮につながります。
あなたがデータ分析を行うビジネスアナリストであろうと、モデルを改良するデータサイエンティストであろうと、アプリケーションに予測機能を追加するアプリケーション開発者であろうと、データサイエンスエージェントは、より的確なガイダンス、透明性、そして制御を提供することで、ビジネス上の疑問から機械学習の結果へと移行するのを支援します。
つまり、Data Science Agentは、Oracle Autonomous AI Databaseからデータを移動させることなく、対話型で統制された高性能な方法で、データのプロファイリング、特徴量の設計、モデルの構築を可能にします。
データサイエンスエージェントの役割
Oracle Data Science Agentは、Oracle Machine Learningを通じてOracle Autonomous AI Databaseに組み込まれた対話型アシスタントです。チャット形式のインターフェースで自然言語を使用して対話することで、機械学習ライフサイクル全体にわたるデータサイエンスタスクのガイダンスや実行を支援します。
データサイエンスエージェントに以下のことを依頼できます。
- 関連するデータセットを発見し、プロファイリングする
- 完全性と分布を評価する
- データを整理し、モデリング用に準備する
- 相関関係を計算し、有用な予測因子を特定する
- 特徴選択と特徴エンジニアリングを実行する
- データベース内の分類モデルと回帰モデルをトレーニングする
- モデルのパフォーマンスを評価および比較する
- 指標と結果を文脈に沿って説明する
- スコアリングと推論のためのSQLを生成する
- キャンペーンに反応する可能性が最も高い見込み客など、予測をランク付けする。
エージェントは会話のやり取り全体を通して会話の文脈を維持するため、以前の作業に基づいて自然な形で作業を進めることができます。例えば、テーブルのプロファイリングを行った後、エージェントに同じデータセットのフィルタリング、特徴量のエンジニアリング、モデルのトレーニング、結果の評価、そして会話の前半で準備したトレーニングデータを使用した推論SQLの生成を依頼することができます。
データサイエンスエージェントは、26aiのXGBoost、サポートベクターマシン、一般化線形モデルなど、データベース内の分類、回帰、異常検知、クラスタリングアルゴリズムを使用できます。
データベース内ネイティブデータサイエンスが重要な理由
データサイエンスプロジェクトは、チームが連携していないツールを切り替えたり、データを別々の環境にエクスポートしたり、セットアップ手順を繰り返したり、プロファイリング、準備、モデリング、デプロイといったタスクを手作業でつなぎ合わせたりすることで、しばしば遅延します。こうした引き継ぎ作業は、コストの増加、ガバナンス上の課題の発生、結果の再現性の困難化につながります。
Data Science Agentは、対話型データサイエンスをOracle Autonomous AI Databaseに直接統合することで、これらの課題の解決を支援します。既存のデータを活用し、Oracle Machine Learningのデータベース内機能を利用することで、分析ワークフローを統制されたエンタープライズデータにより近い場所に維持できます。
これは重要な理由です。なぜなら、次のようなことが可能だからです。
- データの保存場所で作業することで、不要なデータ移動を削減する
- プロファイリング、特徴量エンジニアリング、モデルトレーニング、評価などの反復的なワークフローを短縮する
- アクションログ、生成されたSQL、実行の詳細、および永続的な会話履歴により透明性を向上させます。
- 分析上の決定の背景にある文脈と手順を保存することで、再現性をサポートする。
- 経験の浅いユーザーがガイド付きの説明を通して学習できるよう支援すると同時に、専門家が繰り返し行うタスクを委任できるようにする。
エージェントは、スキーマ内のビューを通じて公開されているリモートソース(データベースリンク経由でアクセスされるソースを含む)とも連携できますが、その場合、権限と構成が制限されます。これにより、チームは管理されたOracle Autonomous AI Databaseのアクセスパターンを維持しながら、複数の環境にわたる統制データを分析できるようになります。
会話型ワークフローの仕組み
データサイエンスエージェントは、ユーザーの作業スタイルに合わせて柔軟に対応できるように設計されています。段階的に操作を進めたり、質問をしたり、中間出力を確認したり、作業を進めながらアプローチを洗練させたりすることができます。また、実行したいタスクに自信が持てるようになったら、ワークフローのより多くの部分を委任することも可能です。
例えば、エージェントに関連データの特定、分布の説明、準備手順の推奨、モデリングオプションの比較などを依頼するなど、対話形式で開始できます。アプローチの妥当性を検証した後、次のようなより大規模な一連の手順を実行するように依頼できます。
「必要な手順を最初から最後まで実行し、最終結果を私に報告してください。」
この柔軟性により、エージェントを使用して反復作業を自動化しながらも、ユーザーは制御を維持できます。データ準備、モデリング、スコアリング、解釈などの重要なステップについては、まずガイド付きの対話から始め、その後、十分に理解されているワークフローを委任して、より迅速な反復作業を実現するのが良い方法です。
モデルのトレーニングやその他の処理にかなりの時間がかかる場合、長時間実行されるジョブを非同期で実行することで、処理が完了するまで他の作業を続けることができます。
ガバナンス、トレーサビリティ、セキュリティ
データサイエンスエージェントは、統制されたエンタープライズデータサイエンスのために構築されています。Oracle Autonomous AI Databaseの権限内で動作するため、スキーマ、テーブル、ビュー、モデルへのアクセスは、ユーザーの役割と権限によって制御されます。
アクティビティの集中度を高め、精度を向上させるために、会話オブジェクトカタログを使用してエージェントが利用できるデータベースオブジェクトの範囲を指定できます。関連するテーブル、ビュー、およびマイニングモデルを登録することで、エージェントはタスクにとって重要なオブジェクトに集中できるようになります。
どのオブジェクトを使用すればよいかわからない場合は、エージェントに許可された範囲内で利用可能なデータを探索するように依頼できます。例:
「私のデータベースには、銀行のマーケティングキャンペーンに関するどのようなデータがありますか?」
トレーサビリティは、このシステムに組み込まれています。ログ、生成されたSQLスニペット、実行の詳細、および永続的な会話履歴は、エージェントが行った操作を理解し、ワークフローを再現し、チームメンバーをオンボーディングし、監査要件をサポートするのに役立ちます。
このエージェントは、効率性とコスト意識を考慮して設計されており、分析タスクを実行する際に、不要なトークンの使用と計算を最小限に抑えるように設計されています。
内部構造はどうなっているのか
データサイエンスエージェントは、オーケストレーションにOracle Select AIエージェントフレームワークを使用します。モジュール式のツールは、プロファイリング、データ準備、モデルトレーニングなどの特定のタスクを実行します。厳選されたプロンプトライブラリはドメインガイダンスを提供し、応答スキーマはユーザーインターフェイスでの信頼性の高い表示のために出力を構造化し、SQL生成はOracle Select AIによって実現されます。
このアーキテクチャにより、エージェントは会話による要求を、管理された実行可能なデータベース内アクションに変換できると同時に、ログ、生成されたSQL、および実行の詳細を通じて透明性を維持できます。
Oracle Select AIと同様に、構成に応じて、サードパーティのAIプロバイダー、OCI Generative AIサービス、またはプライベートにホストするモデルなど、さまざまなAIプロバイダーと大規模言語モデルから選択できます。ドキュメントでは、より良い結果が得られることが知られている大規模言語モデル(LLM)を推奨しています。
例:定期預金キャンペーンの見込み客探し
あなたのチームが定期預金のマーケティングキャンペーンを準備しているとしましょう。利用可能な顧客データとキャンペーンデータを把握し、最も有用な予測因子を特定し、分類モデルを構築し、見込み客の加入可能性に基づいてスコアリングを行いたいと考えています。
まず、図1に示すように、データサイエンスエージェントのアイコンをクリックしてOracle Machine Learningのユーザーインターフェースにアクセスします。すると、図2に示すように、会話一覧ページが表示され、既存の会話を開いたり、新しい会話を作成したりできます。
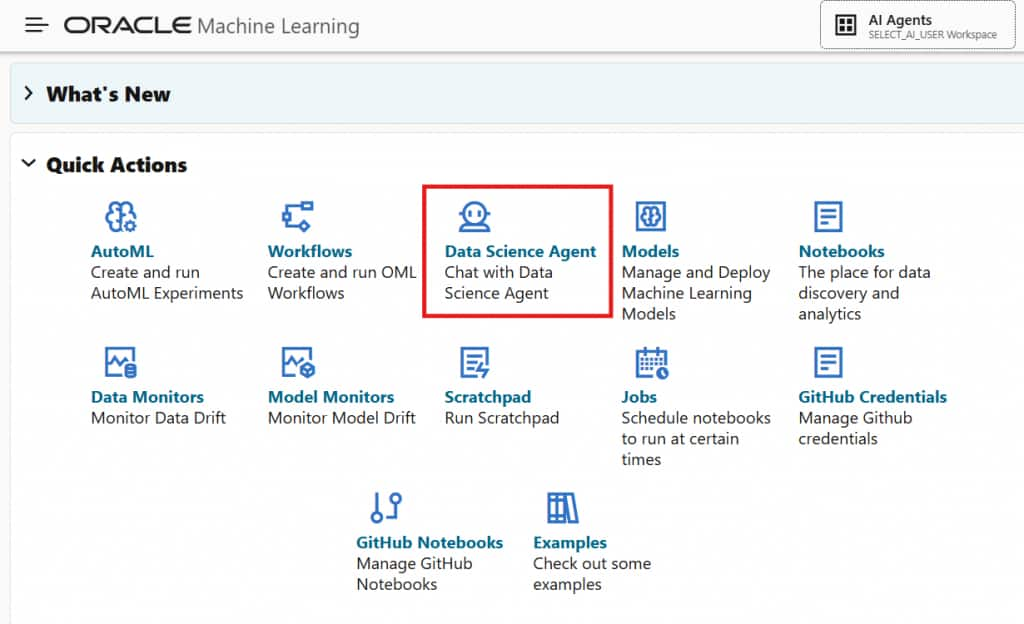
図1:Oracle Machine Learningユーザーインターフェースでデータサイエンスエージェントにアクセスする
新しい会話を作成する際には、AI プロファイルを指定します。このプロファイルには、AI プロバイダ、使用する LLM、および LLM の動作などに影響を与えるその他の属性が含まれます。この AI プロファイルは、DBMS_CLOUD_AI パッケージ、Select AI for Python API、最新の Ask Oracle Select AI チャットボット、Autonomous AI Database Data Studio 設定、または Oracle AI Database Private Agent Factory プラットフォームを使用して作成できます。
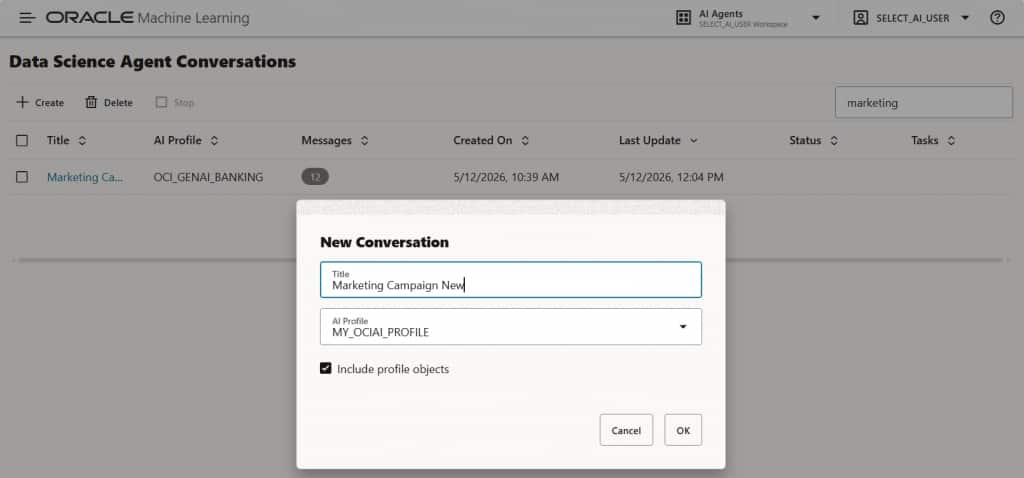
図2:一覧ページから新しい会話を作成する
図3に示すように、新しい会話では、開始するための最初のヒントがいくつか提供されます。
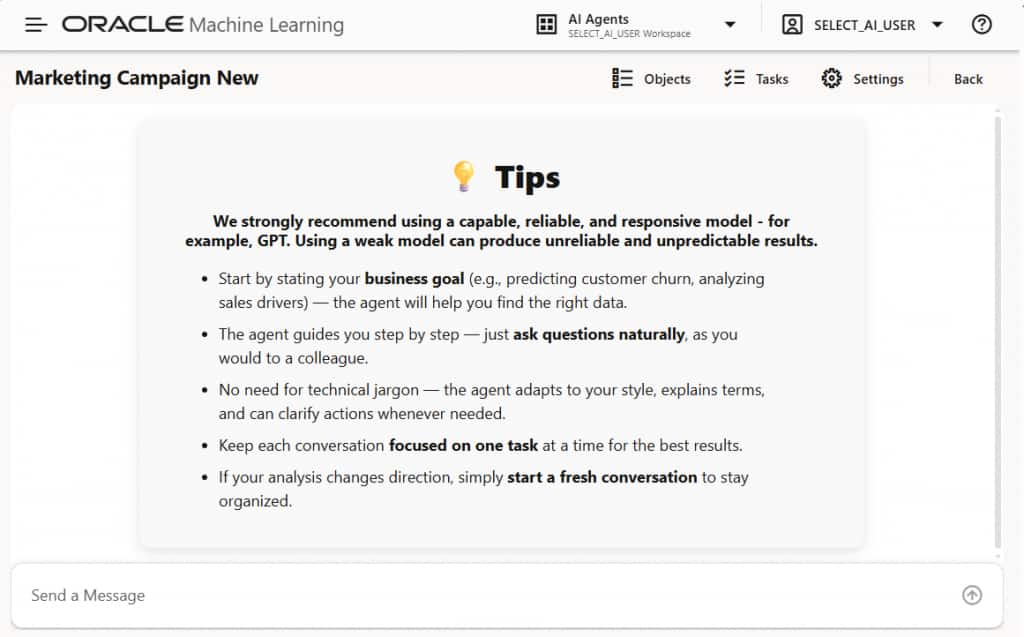
図3:新しい会話を始めるのに役立つヒントがいくつか含まれています
次に、次のようなプロンプトから始めることができます。
「定期預金キャンペーンを開始します。利用可能なカタログ全体から、顧客、過去のマーケティング活動、潜在顧客に関する関連データを見つけるのを手伝ってください。」
データサイエンスエージェントは、図4に示すように、利用可能なテーブル、関連する列、およびデータの使用方法に関する提案を応答として提供できます。顧客属性、過去のキャンペーン結果、コンタクト履歴、その他の予測候補を特定することも可能です。
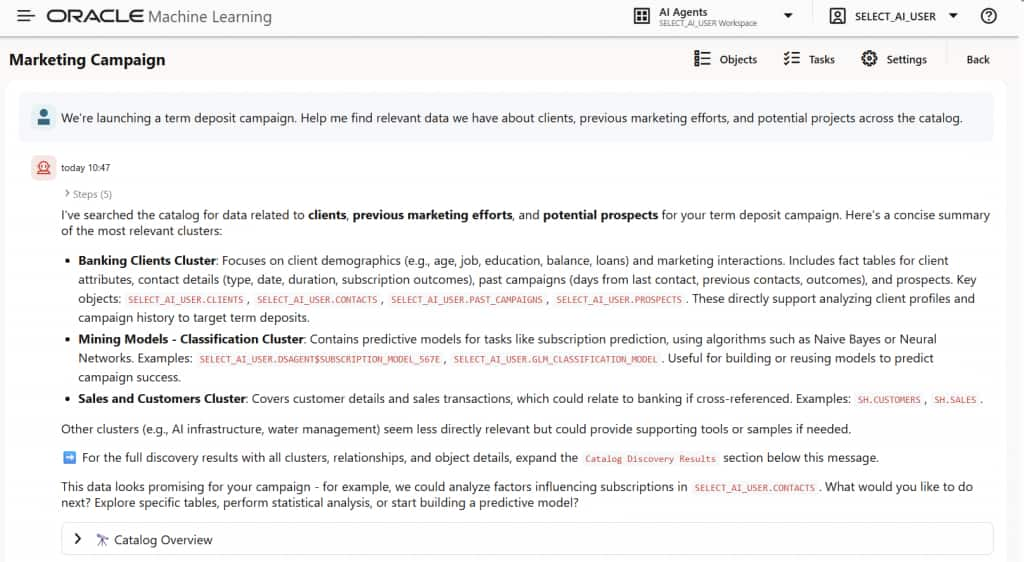
図4:Oracle Data Science Agentにビジネス上の課題を伝える
次に、エージェントにデータのプロファイリングと分析結果の説明を依頼できます。図5に示すように、組み込みの視覚化機能を使用すると、分布、欠損値、変数間の関係などを理解するのに役立ちます。
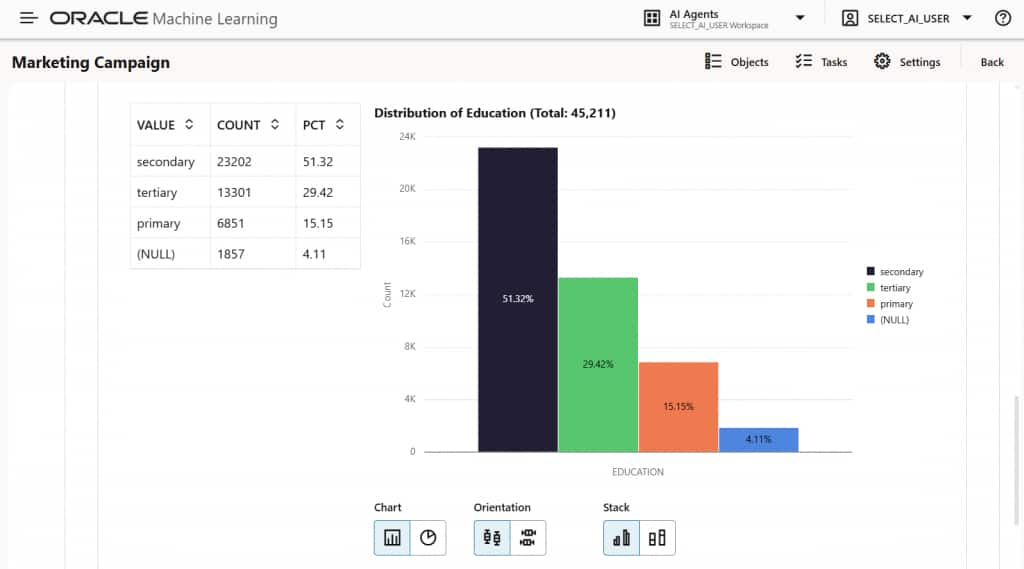
図5:Oracle Data Science Agentによって生成されたデータインサイトを表示する
次に、図6に示すような分類モデルをエージェントに構築させ、図7に示すように、購読する可能性が最も高い上位の見込み客を予測させることができます。データサイエンスエージェントは、データベース内のモデルをトレーニングし、精度や混同行列などの評価指標を表示し、結果を説明し、推論に使用できるSQLを提供できます。また、予測確率に基づいてランク付けされた見込み客識別子を返すこともできます。
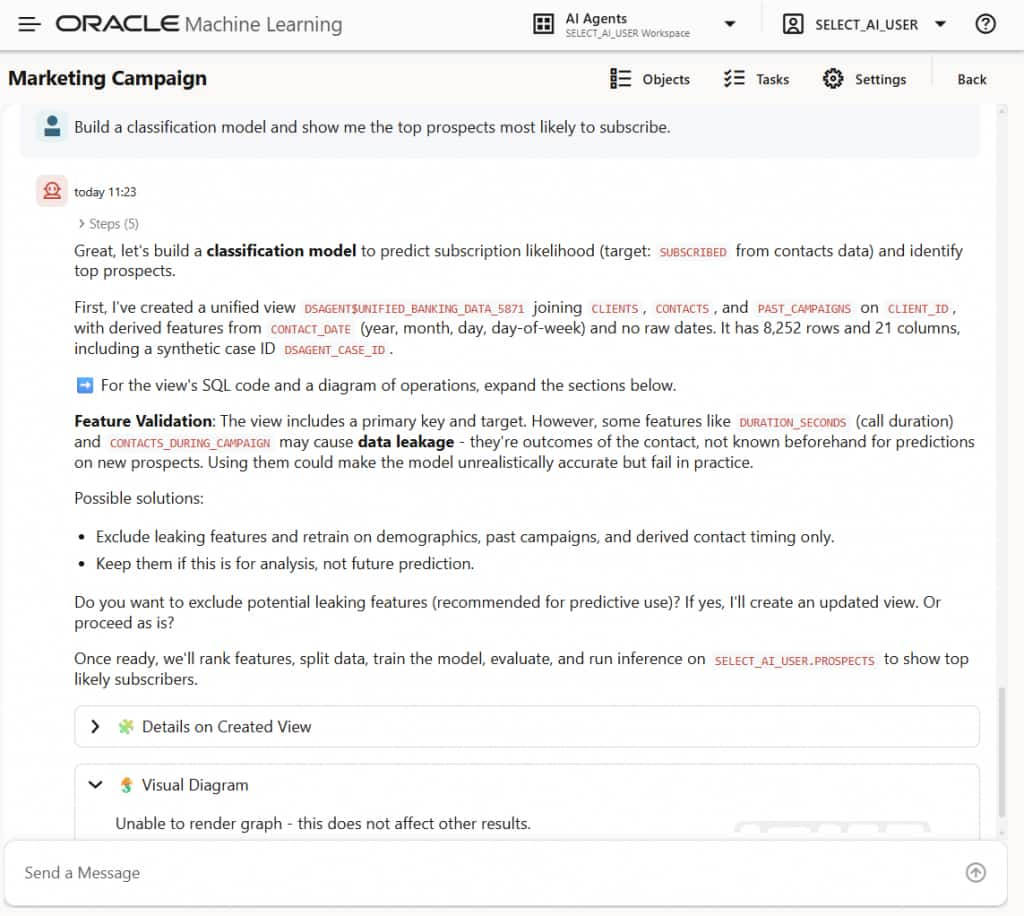
図6:Oracle Data Science Agentにデータベース内機械学習モデルの構築と使用を依頼する
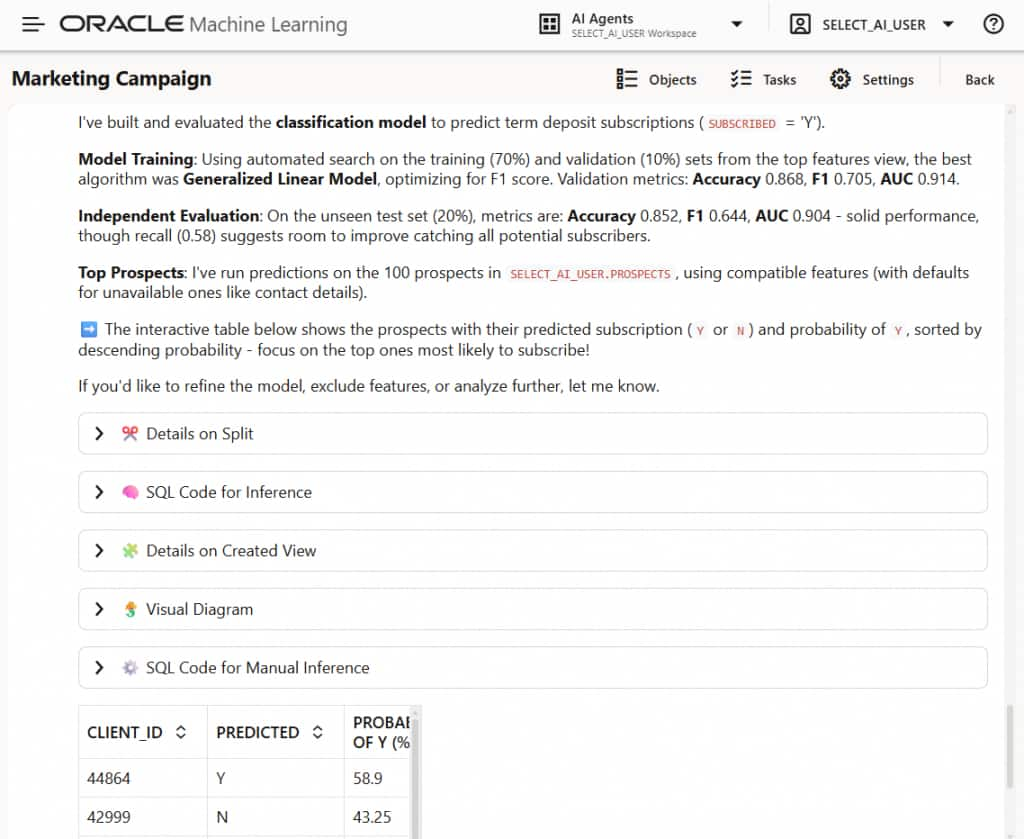
図7:分類モデルのパフォーマンスを確認する
推論用のSQLコードも利用可能で、図8に示すように、アプリケーション開発者が機械学習の結果をアプリケーションに迅速に組み込むのに役立ちます。
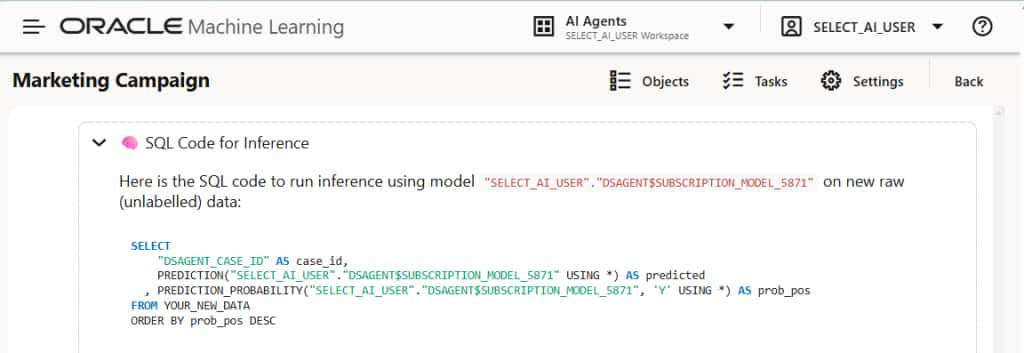
図8:データベース内で直接推論に使用できるSQLクエリを表示する
このフローは、Oracle Autonomous AI Database内で、ビジネス上の疑問からデータ探索、プロファイリング、モデリング、評価、スコアリングまでを単一の対話型ワークフローで進める方法を示しています。
Getting started
データサイエンスエージェントを使用するには、 Oracle Machine Learningが有効になっているOracle Autonomous AI Database Serverless 26aiが必要です。また、ロールと権限に基づいて、関連するスキーマとオブジェクトへのアクセス権も必要です。
それから、
- LLM の認証情報を設定してください
DBMS_CLOUD。 - Oracle Select AIを使用して、AI プロファイルで LLM 設定を定義します。前述のとおり、PL/SQL の DBMS_CLOUD_AI パッケージ、Select AI for Python SDK、Ask Oracle Select AI チャットボット、Autonomous AI Database Data Studio 設定、またはOracle Private Agent Factoryノーコード プラットフォームを使用して AI プロファイルを作成できます。
- Oracle Machine Learning UIコンソールを開きます。
- データサイエンスエージェントのボタンまたはメニューオプションからデータサイエンスエージェントを起動します。
- 関連するテーブル、ビュー、モデルを会話オブジェクトカタログに登録するか、エージェントに依頼して、承認された範囲内で関連データを特定してもらってください。
- 会話を始めて、エージェントにあなたの目的と、どの程度の指導や裁量権を求めているかを伝えましょう。
Oracle Data Science Agentを導入する際には、以下のベストプラクティスを参考にしてください。
- 対話形式で前提条件の検証、生成された手順の確認、プロンプトの調整を開始します。
- ワークフローに自信が持てるようになったら、繰り返し発生する作業や十分に理解している作業を委任しましょう。
- 会話オブジェクトカタログの範囲を厳密に限定することで、精度と効率性を向上させてください。
- 状況をリセットしてエージェントの集中力を維持したい場合は、新しい会話を開始してください。
- 透明性と再現性を高めるため、ログ、生成されたSQL、および実行の詳細を確認する。
- 会話履歴を活用して、プロジェクトを再開したり、チームメンバーをオンボーディングしたり、分析結果を記録したりする。
Oracle Data Science Agentを活用して、データサイエンスの力を最大限に引き出しましょう。
Oracle Data Science Agentは、会話型分析と機械学習をOracle Autonomous AI Database Serverlessにもたらし、データベースからデータを移動することなく、データの探索、特徴量の準備、モデルの構築、結果の評価、推論用のSQLの生成を支援します。
サードパーティのAIプロバイダー、OCI生成AIサービス、または自社でホストするサービスなど、お好みのLLMを使用できます。その際、機械学習ワークフローはOracle Autonomous AI Databaseの権限と構成によって管理されます。ただし、より優れたエクスペリエンスと結果をもたらすことが実証されている推奨モデルがいくつかあります。
Oracle Data Science Agent を試して、Oracle Autonomous AI Database 26ai で対話型のデータベース内機械学習ワークフローの構築を始めましょう。
コメント
コメントを投稿