Oracle Machine Learningワークフローを使用した、コードなしの機械学習パイプラインの構築 (2026/06/02)
Oracle Machine Learningワークフローを使用した、コードなしの機械学習パイプラインの構築 (2026/06/02)
投稿者:Mark Hornick | Senior Director, AI and Machine Learning Product Management
Oracle Autonomous AI Database Serverless の Oracle Machine Learning ユーザー インターフェイスの一部である Oracle Machine Learning Workflow は、コードを記述することなく、視覚的に機械学習パイプラインを構築するのに役立ちます。ドラッグ アンド ドロップ キャンバス、ガイド付き構成、および組み込みの検証機能により、データ準備からモデルのトレーニング、評価、予測、デプロイまでを単一のワークフローで実行できます。OML Workflow は、一般的な機械学習パイプライン タスクをコードなしで実行できるパスを提供すると同時に、OML Notebooks および OML API のコード優先の柔軟性も補完します。
Oracle Machine Learning (OML) アプリケーションに完全に統合された OML Workflow は、OML Notebooks、OML AutoML UI、OML Monitoring、および OML Services を補完し、Autonomous AI Database 内のデータに対して機械学習ワークフローを構築およびデプロイするためのエンドツーエンドのビジュアルなアプローチを提供します。
これが重要な理由
組織は、セキュリティを維持し、ガバナンスを管理し、コストを抑えながら、AIの導入を加速させたいと考えています。これまで、多くのAutonomous AI Databaseユーザーは、Python、SQL、またはRでコーディングしてMLパイプラインを作成してきました。これらのアプローチは強力ですが、時間がかかり、専門的なコーディングスキルが必要です。OML Workflowは、ビジュアルキャンバスとガイド付きエクスペリエンスによってこれらの課題を解決し、チームが以下のことを実現できるようにします。
- アイデアから機械学習モデルへ迅速に移行
- 一般的なタスクを作成する際に、コーディングへの依存度を減らす
- OMLサービスにモデルを簡単にデプロイしたり、SQLクエリから直接データベース内のモデルを使用したりすることで、プロジェクトを運用化できます。
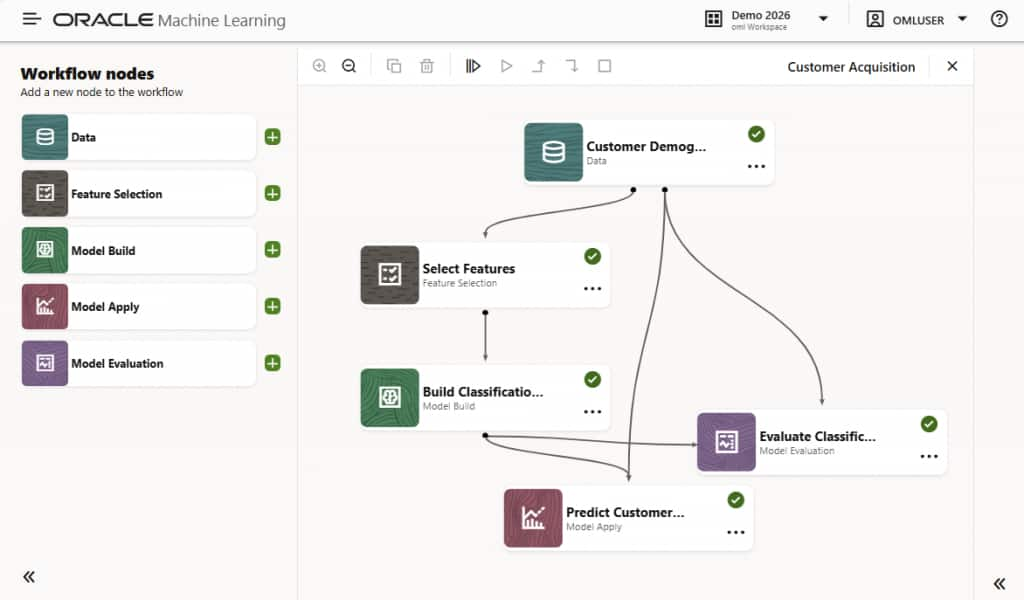
図1:分類のための機械学習ワークフローの例
今日できること
OML Workflowは、機械学習パイプラインの視覚的な構成と実行に重点を置いています。以下のことが可能です。
- 視覚的に構築する:図1に示すように、ノードをキャンバスにドラッグしてパイプラインに接続することにより、エンドツーエンドの機械学習ワークフローを作成します。
- ガイダンスに従って設定する:ノードレベルの設定、定義済みの入力と出力、およびリンクされたステップ全体にわたる組み込みの検証機能を使用します。
- データの準備と特徴量の選択:データベースのテーブルとビューを操作し、統計情報と相関関係を計算し、データを分割し、自動特徴量選択を使用します。
- モデルのトレーニング、予測、評価:構築、適用、評価ノードを使用して、モデルのトレーニング、予測の生成、品質指標の比較を1つのフローで実行します。
- データが存在する場所で実行:自律型AIデータベース環境でOMLを使用してワークフローを実行します。
- ダウンストリームへのデプロイ:選択したモデルをOMLサービスに公開して、リアルタイムの推論、監視、ライフサイクル管理を行うか、SQLから直接データベース内のモデルを使用します。
簡単な例:データからデプロイされたモデルまで
顧客獲得のユースケースを想像してみてください。顧客の人口統計データと、各顧客がアフィニティカード(またはリピーター向けカード)を受け入れたかどうかを示すターゲット列があるとします。ワークフローは次のようになります。
- 顧客テーブルを取得するには、まずデータノードを使用します。
- データを分割します。例えば、80%をトレーニング用、20%をテスト用とします。
- 記述統計量を計算するオプションを選択してください。
- ピアソン相関係数、ケンドール相関係数、またはスピアマン相関係数を用いてデータ相関を計算するオプションを選択してください。結果は図2に示されています。
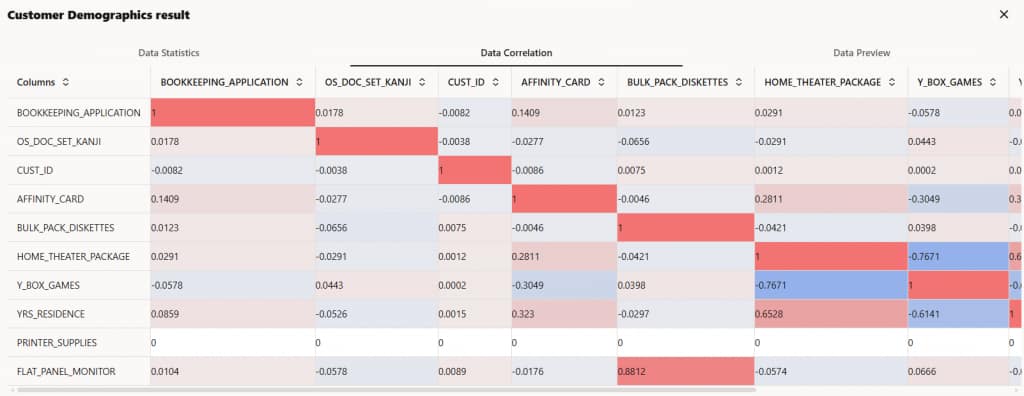
図2:顧客属性データに関する相関分析結果
- 最も予測力の高い属性に焦点を当てるために、特徴選択ノードを追加します。
- 分類モデルをトレーニングするには、モデル構築ノードを追加します。
- モデル評価ノードを追加して、バランス精度スコアや混同行列などの各モデルの品質指標を評価します。結果は図3に示されています。
- ワークフローで選択したモデルを使用して予測を行い、結果を確認するには、モデル適用ノードを追加します。
- あるいは、選択したモデルをOMLサービスに公開して、リアルタイム推論とモニタリングを有効にすることもできます。または、データベース内のモデルをSQLクエリから直接使用することも可能です。
すべての手順は視覚的に表示され、検証されるため、チームは探索段階から生産段階へとスムーズに移行できます。
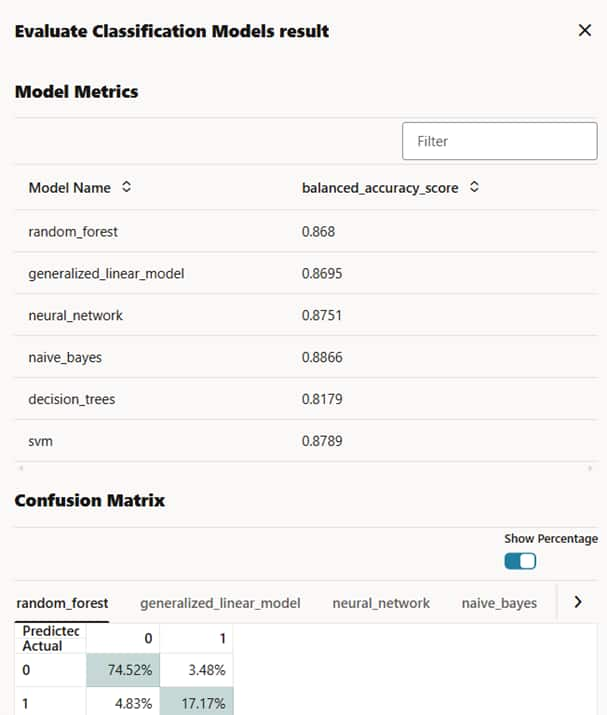
図3:各モデルの指標と混同行列を示すモデル評価結果
Oracle Autonomous AI Database上でエンタープライズ用途向けに構築されています。
OML Workflowは、Autonomous AI DatabaseとOracle Machine Learningプラットフォームのエンタープライズ向け強みを継承しています。
- セキュリティとガバナンス:Oracleのエンタープライズグレードのセキュリティ、ロールベースのアクセス制御、およびデータガバナンスモデルに基づいて構築します。
- パフォーマンスと拡張性:データをデータベースに保持し、OML実行を使用してモデルのトレーニング、評価、適用を効率的に行います。
- 自動更新とパッチ適用:最新の機能やセキュリティ強化を含む、自動パッチ適用と更新のメリットを享受できます。
さらに、OMLワークフローは、Autonomous AI Database上でOMLを使用して既に可能なことを拡張および補完します。
- OML Notebooksは、SQL、PL/SQL、R、PythonのAPIを使用して、コードファーストの探索とカスタマイズを可能にします。データセットの準備と探索、OML APIを使用したカスタムソリューションのスクリプト作成、RおよびPythonエコシステムのパッケージの利用が可能です。
- OML AutoMLは、ノーコードのユーザーインターフェースとPython APIから、自動的な分類および回帰モデリングをサポートします。
- OML Monitoringは、データとモデルの監視のためのノーコードユーザーインターフェースをサポートしており、時間の経過に伴うドリフトとそのモデル品質への潜在的な影響を追跡できます。
- OML Servicesは、 RESTを使用してモデルのデプロイ、監視、バイアス検出、ライフサイクル管理をサポートします。OML WorkflowはOML Servicesと自然に連携し、本番環境へのデプロイを効率化します。
既存のAutonomous AI DatabaseインスタンスでOMLワークフローを試すか、Always Freeインスタンスを作成してOracle Machine Learningを体験してください。
リソース
詳細については、以下をご覧ください。



コメント
コメントを投稿