HAアプリケーション開発: 開発者の高可用性への道のり (2026/01/30)
HAアプリケーション開発: 開発者の高可用性への道のり (2026/01/30)
https://blogs.oracle.com/developers/ha-app-dev-a-developers-journey-to-high-availability
投稿者:Irina Granat | Senior Director
Richard Exley | Consulting Member of Technical Staff, Oracle Database
多くの開発者は、理想的な条件下でコードが正しく動作することに集中していますが、もし障害が発生した場合はどうなるでしょうか?アプリケーションインスタンスがクラッシュしたり、メンテナンス作業を行ったりした場合、エンドユーザーにはどのような影響があるでしょうか?単なる迷惑にとどまらず、コストがかかり、ユーザーの信頼を著しく損なう可能性があります。業界調査によると、数分間のダウンタイムでも数千ドルの損失が発生し、ブランドに永続的な影響を与える可能性があると推定されています。
はじめに
多くの開発者は、ハッピーパスを最適化しようとします。しかし、本番環境では障害は避けられず、一度のクラッシュやメンテナンス期間が波及し、コストの増大、ユーザーの不満、そして信頼の低下につながる可能性があります。高可用性(HA)は、もはやサーバーやデータベースだけにとどまらず、アプリケーションの設計、構築、そして構築方法に関わるものです。
Oracle Maximum Availability Architecture(MAA)チームは、20年以上にわたり、企業のプラットフォームレベルでの稼働率向上を支援してきました。しかし、HAはインフラストラクチャ層だけにとどまりません。このプロジェクトでは、「開発者が同じ規律をアプリケーション自体に適用したらどうなるだろうか?
耐障害性を後付けで考えるのではなく、最初から設計に組み込んだらどうなるだろうか?」という問いを投げかけました。
重要なポイント: 高可用性とは、単に「稼働」しているということではなく、問題が発生した場合でも確実に高速で応答することです。
これは、HAアプリ開発のベストプラクティスシリーズの最初の投稿です。このシリーズでは、代表的なアプリケーションの作成とテストを通して発見した技術的な原則、実際の課題、そしてベストプラクティスを共有します。理論に固執するのではなく、アーキテクチャの選択とコードパターンがどのように測定可能な可用性の向上をもたらすかを示します。
さあ、参加してみましょう。
アプリにとってHAが重要な理由:プロジェクトの前提
従来、HAは運用上の問題でした。しかし今日では、ユーザーは障害発生時でも応答性を期待しているため、開発者はHAをデプロイメントだけでなくアプリケーション設計にも組み込む必要があります。
このプロジェクトは、可用性は後付けではなく、根本から統合されるべきであることを実証するために開始しました。そこで、実際のアプリケーションを開発し、実際の障害をシミュレーションし、あらゆる情報を追跡し、実際に何が役立つのかを探るために継続的に実験を行いました。
可用性とは、単に「稼働中」であることではありません。アプリケーションが200 OKを返したとしても、応答に時間がかかりすぎると、ユーザーは依然としてそれを障害と認識します。真の可用性とは、アプリケーションが稼働し、期待通りに動作し、ユーザーが作業を継続できるほどの速さで応答していることを意味します。
ある程度のダウンタイムは避けられませんが、私たちの目標はアップタイムを最大化し、「オンライン/オフライン」の状態だけでなく、実用的な回復力を測定することでした。ユーザーの実際の体験、つまり速度、正確性、信頼性に焦点を当てることで、アプリの真の可用性を向上させることができました。
プロジェクト開発の秘密
開発者の観点から HA を検討するために、次の 2 つのエンドポイントを持つシンプルな RESTful サービスを構築しました。
- GET /user/{uid}: ユーザー情報を取得する
- PUT /user: ユーザー情報を挿入または更新する
アプリは意図的に最小限に抑えられています。私たちの目標は複雑なビジネスロジックではなく、アーキテクチャとコードの選択が可用性、パフォーマンス、そしてリカバリにどのような影響を与えるかをテストすることでした。シンプルさを保つことで、結果を幅広く適用できるようにしました。
私たちは成功と失敗を、ユーザー目線で厳密に定義しました。
- 有効な応答の場合は HTTP 200
- データが見つからない場合のHTTP 404
- HTTP 5xxエラーは許可されません。5xxはすべてダウンタイムとして扱われます。
- 応答は常に 50 ミリ秒未満です。外れ値はサービス中断としてカウントされます。
リアルタイムでHAを測定
現実世界の状況を想定し、厳格なSLAを設定しました。成功はHTTP 200レスポンスで名前が返されることと定義し、不明なIDの場合はHTTP 404を使用しました。失敗にはHTTP 5xxステータスが含まれます。
パフォーマンスについては 、1秒あたり1,000リクエスト(うち10%はPUTリクエスト)の負荷をかけました。 リクエストが最終的に成功したか失敗したかに関わらず、リクエストあたり最大50ミリ秒のレイテンシを強制し、外れ値は許容しませんでした。
プレッシャーの下での効率をテストするために 、 1 秒あたり 1,000 件のリクエストを配信しながら、 アプリケーションの データベース接続を最大 8 つに制限しました。
私たちの 可用性の 定義は厳格で、 5xxレスポンス、または50ミリ秒を超えるレイテンシのリクエストはすべてサービス停止とみなしました。目標は、停止中でも最大限の可用性を実現することでした。
この意図的に厳しい SLA により、どのフレームワークが実際にストレスに対処しているかを確認し、システムが稼働時間だけでなく、高速で信頼性が高く予測可能なサービスを提供できるようにしました。
可用性の定義方法を変更することで、会話は単にオンラインかどうかを尋ねることから 、特にストレス下で応答性と信頼性があるかどうかを尋ねることに移行しました。
実世界のためのストレステスト
アプリを起動して実行した後、高負荷の状態でテストを実施し、計画的な停止と計画外の停止の両方をトリガーしました。
- データベース接続のドロップアウト
- サーバークラッシュ
- ネットワークの問題
私たちは、ただスムーズに進むようにテストしていたわけではありません。本番環境では問題が起きる可能性があるため、問題が発生する可能性のあるすべてを再現することを目指しました 。
私たちは、システムが生き残れるかどうかだけで なく、どれだけ速く検知し、対応し、回復できるかを知りたかったのです。
- 応答時間: 混雑時に成功したリクエストと失敗したリクエストの両方をどれだけ早く処理したか
- 回復力: 失敗シナリオでどのように行動したか
- 回復速度: システムがダウンした後にどれだけ早く回復したか
同じアプリ、8つのフレームワーク
結果を有意義なものにするために、同じアプリを 8 つの最新スタックに移植し、すべてのフレームワークに同じ厳格な SLA を適用しました。
- パフォーマンス: 厳格な 50 ミリ秒のサービス レベル契約で 1 秒あたり 1,000 リクエスト
- 効率: 接続プールを実際にテストし、リソースの過負荷を回避するために、データベース接続を 8 つに制限します。
- 可用性: 5xx エラーや応答の遅延は、例外なくハード ダウンタイムを意味します。
これらの制約により、フレームワーク間の弱点、トレードオフ、最適化が明らかになり、言語、フレームワーク、ドライバーの成熟度について同等の比較が可能になりました。
- Javaサーブレット
- UCP と HikariCP を使用した Spring Boot
- Node.js(JavaScript)
- Node.js(TypeScript)
- .NET C#
- Python
- Rust
- Go
ネタバレ注意:すべてのスタックが障害を適切に処理できるわけではありません。今後の投稿で、その違いについて詳しく説明します。
Oracle Cloud上で構築およびテスト済み
これらはすべて、 Oracle Cloud Infrastructure (OCI)上で以下の 機能を使用して実行されました。
- Oracle AI Database 26ai
- 結果を保存および視覚化するためのAutonomous AI Dataase + APEX
この設定により、単なるラボ実験ではなく現実世界の環境が得られ、ダッシュボードやグラフを使用して結果をすばやく分析できるようになりました。
テストには Oracle Cloud を選択しましたが、HA の概念、原則、教訓は、クラウド プロバイダやデプロイメント環境全体に広く適用できます。
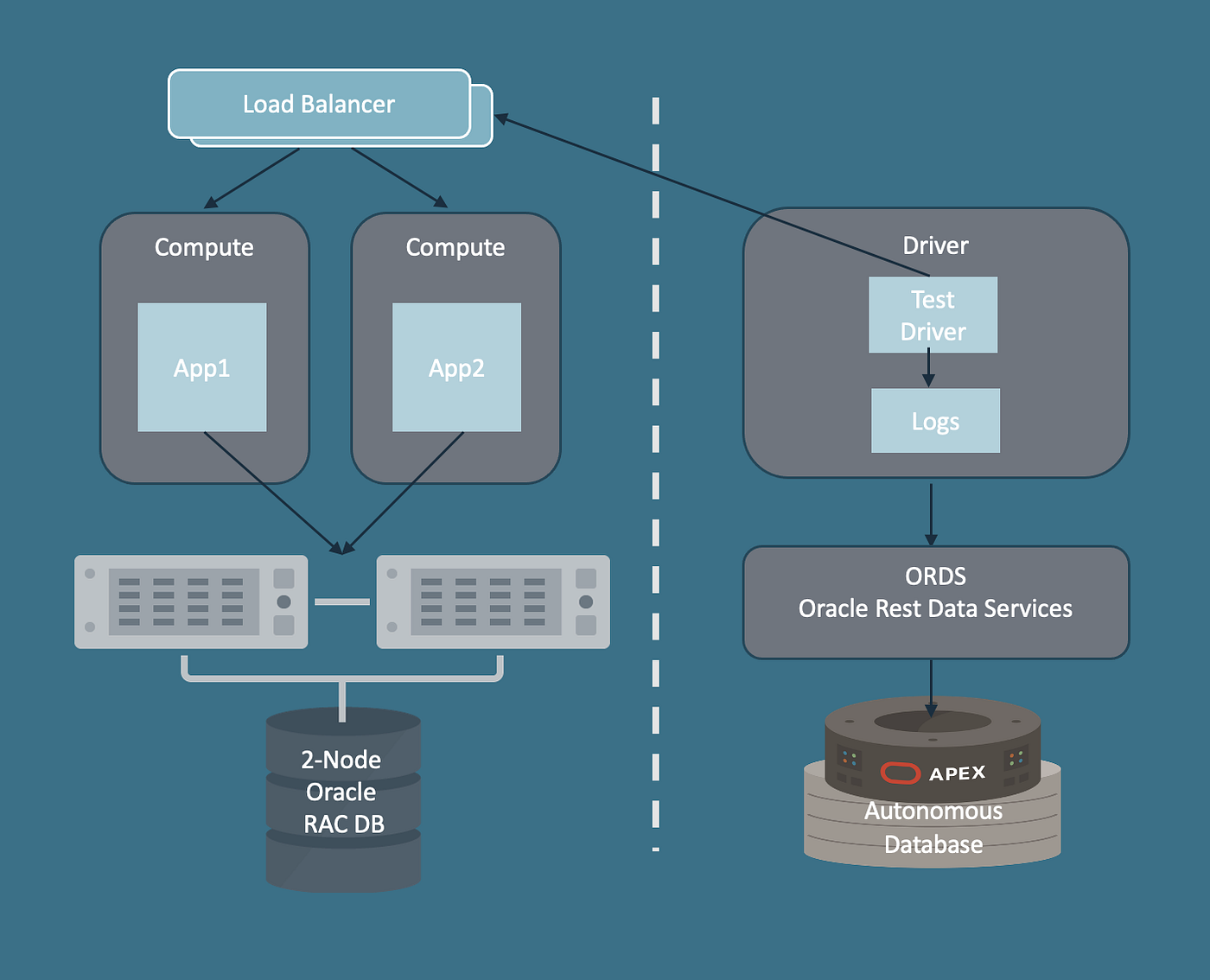
今後のブログ投稿では、このテスト ハーネスのアーキテクチャを詳しく説明し、各コンポーネントが HA にどのように貢献したかを探り、実際のテスト結果と得られた教訓を共有します。
次は何?
これはほんの基礎に過ぎません。今後の投稿では、アプリケーションアーキテクチャやロードバランサから接続プール、実際のフェイルオーバーテストに至るまで、レジリエンスの層を段階的に説明していきます。
- 高可用性のためのアプリケーションアーキテクチャの設計
- ロードバランサが障害を検出して対応する仕組み
- フレームワーク間の接続プーリング戦略
- 計画的および計画外の実際のフェイルオーバーシナリオ
- 実際のテスト結果、ログ、グラフ
また、選択したテクノロジー スタックに関係なく、最初から HA を設計するのに役立つ実用的なヒントとサンプル コード パターンも紹介します。
私たちの目標は、開発者にとってHAを実用的なものにすることです。結局のところ、高可用性はコーディング後に散りばめるものではなく、最初の行からすべてのレイヤーに設計に組み込まれるものだからです。
当社のテスト基準は意図的に厳格ですが、ユーザーエクスペリエンスに支障をきたすことなく、各プラットフォームがどの程度の余裕を提供するかを明確に示しています。コスト、複雑さ、そして真のHAの間のトレードオフは、すべてのエンジニアリングチームが検討すべき課題です。
乞うご期待!



コメント
コメントを投稿