Oracle Cloud Infrastructure(OCI)HPCスタック – リリース(3.0.0) (2026/04/10)
Oracle Cloud Infrastructure(OCI)HPCスタック – リリース(3.0.0) (2026/04/10)
https://blogs.oracle.com/cloud-infrastructure/oci-infrastructure-oci-hpc-stack-release-3
投稿者:Irshad Buchh | AI/ML Solutions Engineer
Arnaud Froidmont | HPC Solution Architect
Mac Stephen | Principal Cloud Engineer | HPC/AI/ML
はじめに
Oracle Cloud Infrastructure (OCI) は、過去数年間にわたり高性能コンピューティングに多大な投資を行ってきました。OCI HPC スタックは、5年以上前に誕生して以来、大きく成熟してきました。リリースごとに、スタックはますます複雑なワークロードとデプロイメントパターンをサポートするように進化してきました。このブログでは、HPC/GPU クラスタのデプロイメント、構成、ライフサイクル管理を簡素化する新しいパラダイムをもたらすメジャーアップデートであるOCI HPC Cluster Stack 3.0.0を紹介します。リリース 3.0.0 では、新しい自動化、アーキテクチャの改善、よりモジュール化された設計が組み込まれており、大規模クラスタの運用がこれまで以上に容易になります。
大規模なAIトレーニングおよび推論ワークロードが拡大し続けるにつれ、顧客はRDMA対応ネットワークによって実現される高速かつ低遅延のノード間通信を備えた、緊密に連携したGPUクラスタを必要としています。OCIのHPCクラスタスタックは、OCI HPCチームが設計および検証したTerraformおよびAnsibleアーティファクトを使用して、このようなクラスタを効率的にデプロイするための手段を提供します。
単一のデプロイメントで、スタックは以下を含む完全なクラウドネイティブHPC/GPU環境をプロビジョニングします。
- パブリックサブネット、プライベートサブネット、クラスタネットワーク、および制御された安全なアクセスを確保するために必要なすべてのゲートウェイ(IGW、NAT、SRGなど)とセキュリティリストで構成されたVCN。
- パブリックサブネットにデプロイされたコントローラーノードは、クラスターの管理プレーンおよび管理ハブとして機能します。クラスターの運用に必要な自動化スクリプト、構成ユーティリティ、およびツールがプリロードされています。
- 同じくパブリックサブネット内に配置されたログインノードは、ユーザーにジョブの送信、アプリケーションのコンパイル、共有リソースへのアクセスを行うための安定した環境を提供する。
今回の新リリースは、OCIの実績あるHPC基盤を基盤としつつ、AIおよび科学計算ワークロード向けにGPUアクセラレーション対応クラスターを導入する際のパフォーマンス向上、運用簡素化、および価値実現までの時間短縮を実現する機能強化を導入しています。
略歴
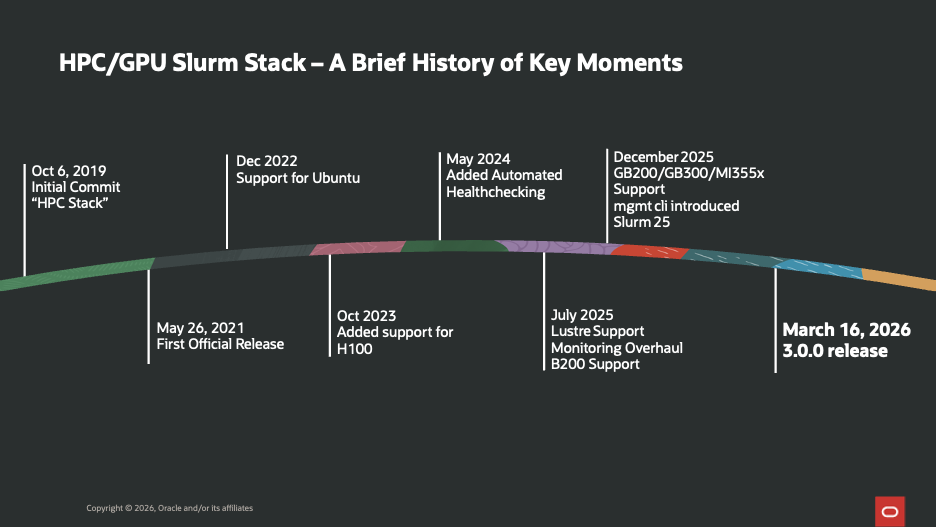
OCI HPC/GPU Slurmスタックは、拡張性と高性能を備えたAIおよびHPCワークロードに対する顧客ニーズの高まりを受けて、ここ数年で大きく進化を遂げてきました。2019年に最初のコミットメントとして始まったこのソリューションは、2021年の正式リリースをもって、クラウドベースのHPC導入のための強固な基盤を築き、実運用可能なソリューションへと急速に成熟しました。
採用が拡大するにつれ、このスタックはより幅広いエコシステムをサポートするために機能を拡張しました。2022年にはUbuntuのサポートが導入され、多様な企業環境に対応できる柔軟性が向上しました。AI/MLワークロードの急速な進歩に伴い、2023年にはNVIDIA H100 GPUのサポートが追加され、顧客は次世代のトレーニングおよび推論ワークロードを大規模に実行できるようになりました。
2024年と2025年には、イノベーションのペースがさらに加速しました。自動化されたヘルスチェックによりクラスタの信頼性と運用効率が向上し、Lustreのサポートや監視システムの刷新といった機能強化によってパフォーマンスの可視性が強化されました。B200などの新しいGPUアーキテクチャや、GB200/GB300、MI355xといった次世代システムへの対応は、ハードウェアの進歩に常に先んじるというスタックの姿勢を示すものでした。管理CLIの導入とSlurm 25との統合により、クラスタ運用はさらに効率化されました。
これらのマイルストーンはすべて、3.0.0リリース(2026年3月)で頂点に達し、使いやすさ、拡張性、エンタープライズ対応性において大きな前進を遂げ、OCI上の最新のAIおよびHPCワークロード向けの包括的なソリューションとなります。
イベント駆動型クラスタ自動化と動的スケーリング
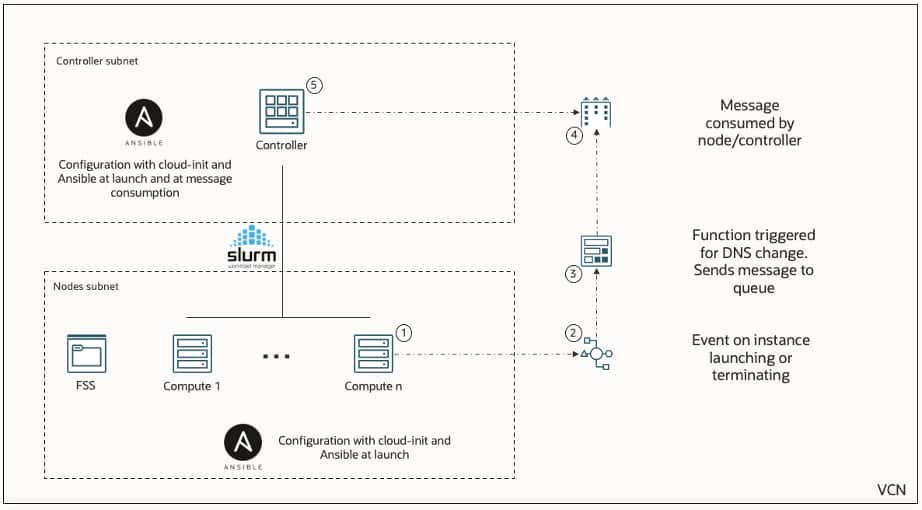
Stack 3.0 の主要なアーキテクチャ強化点の 1 つは、OCI サービスと Slurm ベースのクラスタ操作を緊密に統合するイベント駆動型自動化フレームワークの導入です。この設計により、リアルタイムイベントに基づいてコンピューティングノードの動的かつインテリジェントなライフサイクル管理が可能になります。クラスタ内でコンピューティングインスタンスが起動または終了されると、OCI イベントが生成されます。このイベントによってサーバーレス関数がトリガーされ、キューにメッセージが発行されます。コントローラノードはこのキューからメッセージを継続的に消費し、Slurm ノードの状態の更新、新しいノードの登録、廃止されたノードの削除など、適切なアクションを実行します。
同時に、プロビジョニング時にコントローラーノードとコンピュートノードの両方がcloud-initとAnsibleを使用して構成されるため、クラスター全体で一貫性のある再現可能なセットアップが保証されます。インフラストラクチャの自動化とイベント駆動型オーケストレーションの組み合わせにより、手動による介入が不要になり、運用上のオーバーヘッドが削減され、Slurm内のクラスター状態が常に基盤となるOCIインフラストラクチャと同期することが保証されます。全体として、このアーキテクチャは従来のHPC環境にクラウドネイティブな柔軟性をもたらし、顧客は信頼性と運用効率を維持しながらGPUクラスターをシームレスに拡張できます。
デプロイメント
カスタムネットワーク、クラスタチューニング、CI/CD統合、特殊なGPU構成など、より高度な制御を必要とするチーム向けに、完全なコードベースがGitHubで公開されています。このデプロイメントにより、変数、Ansibleプレイブック、アーキテクチャコンポーネントを自由にカスタマイズできます。
手順:
- GitHubリポジトリにアクセスしてください:https://github.com/oracle-quickstart/oci-hpc/
- 前提条件、設定変数、モジュールの説明については、READMEファイルを確認してください。
- Oracle Resource Managerを使用して直接デプロイするには、「Oracle Cloudにデプロイ」ボタンをクリックします。
リソースマネージャーは入力変数を要求し、その後Terraformプランを実行して、コントローラー、ログイン、GPU/CPU計算ノード、およびサポートするネットワーク構成要素を含む完全なHPCスタックを構築します。
ノード構成
ノード構成は、よりモジュール化され、分散化され、スケーラブルになるように再設計されました。クラスターは、以前のリリースで使用されていた使い慣れた Ansible ベースの自動化フレームワークを引き続き活用していますが、ワークフローが強化され、各ノードが自己構成できるようになり、コントローラーへの依存度が低減され、大規模展開時の全体的な信頼性が向上しました。クラスター全体で一貫性を確保するため、Ansible プレイブック、ロール、テンプレートなどのすべての構成アーティファクトは、/config ディレクトリの下に一元的に保存されます。このディレクトリは、OCI マネージド NFS サービスを使用してすべてのノードにエクスポートされます。
共有パス /config にカスタム Ansible ロールを作成または変更すると、環境内のすべてのノードで即座に利用可能になります。GPU ノードでも CPU ノードでも、各計算ノードは構成ワークフローを独立して非同期的に実行します。
クラスタ管理ユーティリティ(mgmt)
OCI HPC Cluster Stack 3.0.0では、HPCおよびGPUクラスタの日常的な管理操作とライフサイクル管理を簡素化するために設計された、強化されたクラスタ管理ユーティリティ(mgmt)が導入されました。このユーティリティはコントローラノードにインストールされ、 OCI APIと直接連携してルーチンおよび高度なメンテナンス作業を実行できる統合コマンドラインインターフェイスを提供します。
mgmtユーティリティはクラスタの運用の中枢として機能し、管理者がOCIコンソールやTerraformの状態を手動で操作することなく、クラスタを効率的に管理、検査、変更できるようにします。このユーティリティは、以下のコマンドグループを含む複数の機能群を整理しています。
- クラスター
- 設定
- データベース
- ファブリック
- ログイン
- ネットワーク
- ノード
- 推奨事項
- サービス
利用可能なコマンドを確認するには、次のように実行してください:
mgmt –help
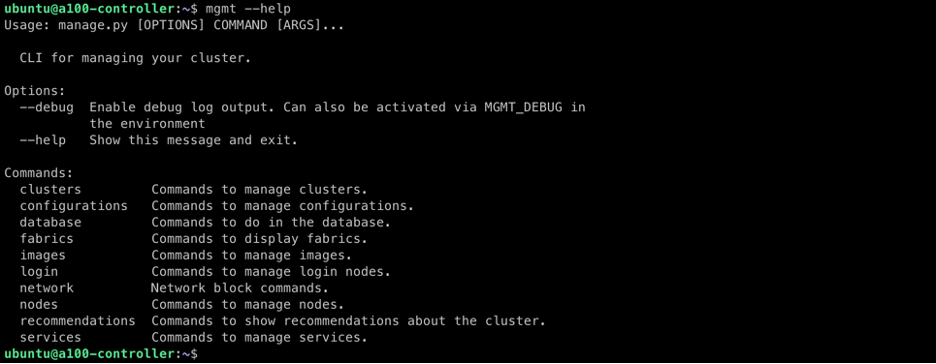
各コマンドカテゴリには、特定の操作タスクに合わせて調整されたサブコマンドが含まれています。各カテゴリの構文ヘルプは、以下の方法で簡単にアクセスできます。
mgmt <コマンド> –help
以下に、よく使用されるコマンドをいくつか示します。
1. クラスタのノード一覧を表示する
mgmt nodes list –cluster a100

2. シリアル番号、IPアドレス、OCID、またはホスト名でノード情報を照会する
管理ノードが任意のGPUを取得する-2538
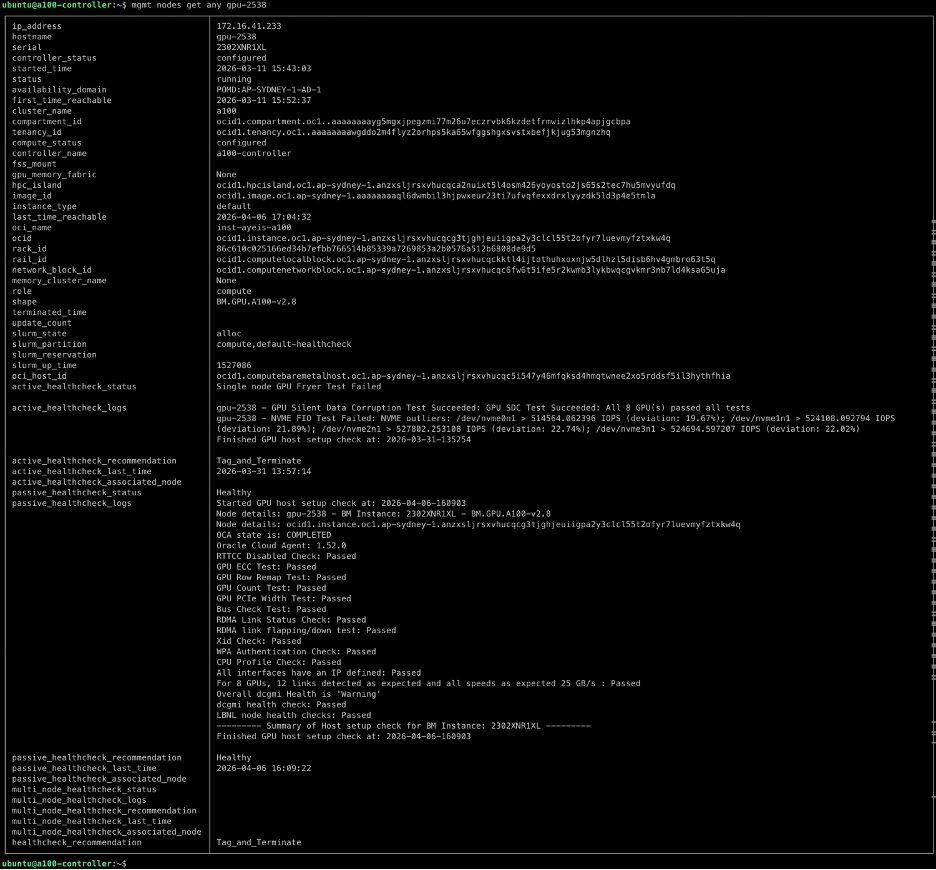
クラスターヘルスオートメーション
OCI HPC Cluster Stack 3.0.0には、NVIDIAおよびAMD製GPUの最適なパフォーマンスと信頼性を確保するための、強化されたGPUヘルスモニタリング機能が搭載されています。これらのヘルスチェックは、包括的なモニタリングソリューションの一部として自律的に実行される、自動化されたパッシブおよびアクティブヘルスチェックによって実現されます。
パッシブチェックは、GPUを占有したり実行中のワークロードに影響を与えたりすることなく定期的に実行され、ノードがアイドル状態のときにアクティブチェックがGPUストレステストを実行し、NVIDIA GPUの場合はNVIDIA Collective Communication Library(NCCL)、AMD GPUの場合はROCm Communication Collectives Library(RCCL)を使用して、シングルノードとマルチノードの両方の通信パフォーマンスを評価し、RDMAクラスタ内のGPU間でのデータ交換の効率を検証します。
これらのヘルスチェックの結果と、NVIDIA DCGM ExporterおよびAMD SMI Exporterを通じて収集された追加の監視データは、事前に構成されたGrafanaダッシュボードに集約され、お客様のご都合に合わせて視覚化されます。これらのダッシュボードは、クラスター、ノード、およびGPUレベルでの洞察を提供し、HPC環境のプロアクティブな保守と最適化を促進します。詳細については、GPUクラスターの監視に関する最新のブログ記事をご覧ください:https://blogs.oracle.com/cloud-infrastructure/high-performance-gpu-fleet-visibility
便利な機能
複雑で大規模なGPU/HPCクラスタの管理をよりセルフサービス化し、全体的に容易にするために、いくつかの便利な機能がスタックに追加されました。上記に挙げた詳細情報の表示、ヘルスチェック、ノードの追加/削除といった基本的なコマンドに加え、高度なOCIツール向けの自動化機能が管理ツールセットに組み込まれ、システム管理のさらなる支援と自動化を実現しています。
これには以下が含まれます。
- OCIイメージ管理
- ブートボリュームの交換
- ギャザリングコンソール履歴
- Ansibleの再構成
- マルチノードコマンド実行
- Slurmの自動設定
- 異常なノードのタグ付けと終了
従来、このような操作には、エンジニアリングによるシステム強化やスクリプト作成が必要だったり、コンソールから手動で行う必要がありました。今回、これらの機能を独自の推奨エンジンに組み込み、自動ヘルスチェックと連携させることで、クラスタ内のノードに対して推奨されるすべてのタスクを一度にまとめて実行できるようにしました。
経営陣の推奨事項リスト

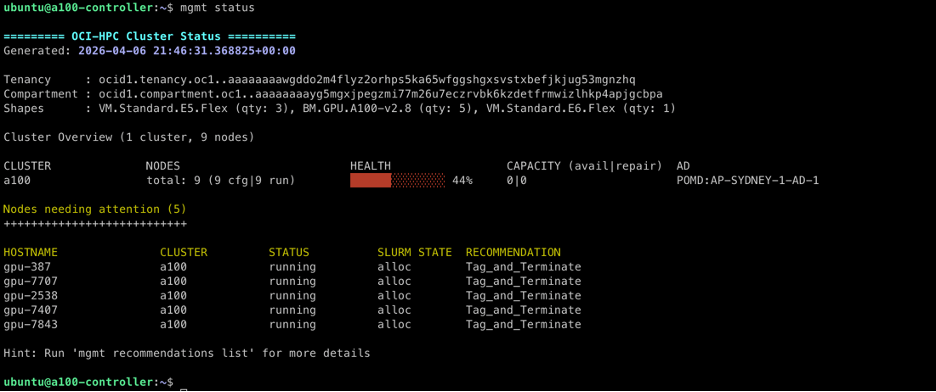
管理ステータス
まとめ
OCI HPC Cluster Stack 3.0.0のリリースは、AI、科学シミュレーション、そしてそれ以外の分野のニーズに合わせて最適化された、スケーラブルで高性能なコンピューティング環境をお客様に提供するというOracle Cloud Infrastructureの取り組みにおける重要な進歩です。モジュール式のノード構成、運用を効率化する直感的な管理ユーティリティ、堅牢なGPUヘルスモニタリング、そして便利な機能群を導入することで、このアップデートは大規模クラスタの導入の複雑さを大幅に軽減し、信頼性を向上させ、インサイト獲得までの時間を短縮します。OCIはHPCおよびGPUテクノロジーにおける革新を継続しており、このリリースをお試しいただき、お客様の最も野心的なコンピューティング課題に対する新たな可能性を解き放っていただくことをお勧めします。



コメント
コメントを投稿