データ抽出ツールで使用されるREST APIの概要 (2026/05/20)
データ抽出ツールで使用されるREST APIの概要 (2026/05/20)
https://www.ateam-oracle.com/introducing-rest-apis-used-by-the-data-extraction-tool
投稿者:Elói Lopes | Cloud Solution Architect
このブログでは、データ抽出ツールで使用されるREST APIの一部について解説します。これらのAPIはデータ抽出ツールが所有するものではありませんが、関連ドキュメントの更新作業が完了するまでの間、ツール内でのAPIの使用方法に焦点を当てて説明します。ブログのタイトルは、より広範な内容を反映させるために、今後変更される可能性があります。
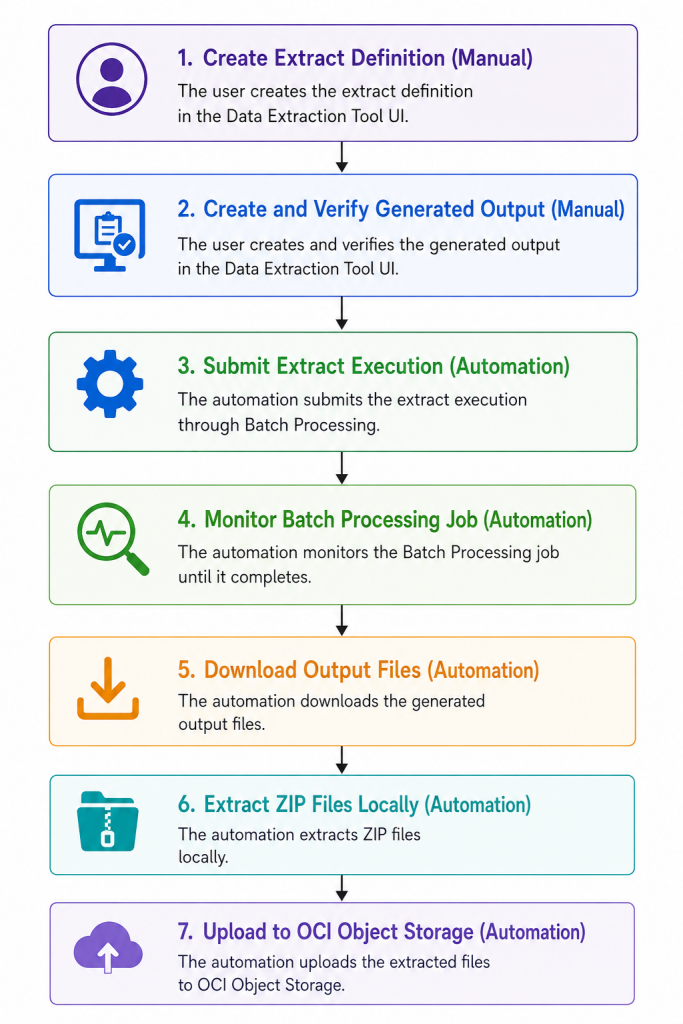
データ抽出パイプラインは、多くの場合、手動ワークフローから始まります。抽出を定義し、実行し、完了を待ち、出力をダウンロードし、ファイルを解凍し、後続の処理で使用できるように永続的な場所にアップロードします。
この記事では、既存のデータ抽出処理を自動化し、結果のファイルをOCIオブジェクトストレージに格納するための実践的な手順を説明します。抽出定義自体は、オブジェクト、属性、出力形式、フィルタの選択がより簡単で使いやすいデータ抽出ツールUIで作成します。抽出定義が作成されると、ワークフローはOAuthベースのAPIアクセスを使用し、バッチ処理ジョブを送信し、ジョブを監視し、出力ファイルをダウンロードし、ZIPアーカイブを解凍し、最終的なデータファイルをOCIオブジェクトストレージバケットにアップロードします。
パイプラインの機能
大まかに言うと、このパイプラインは以下の手順を実行します。
- データ抽出ツールのユーザーインターフェースで抽出定義を作成します。
- 設定と認証情報を安全に読み込みます。
- データ抽出API用のOAuthアクセストークンをリクエストします。
- 抽出処理のためのバッチ処理を送信してください。
- バッチ処理ジョブが完了するまで、そのジョブをポーリングします。
- ジョブによって生成された出力ファイルを一覧表示します。
- 出力ファイルをダウンロードしてください。
- ZIPファイルを解凍してください。
- 抽出したファイルをOCIオブジェクトストレージにアップロードします。
アーキテクチャの概要
このパイプラインは、主に3つのシステムを接続しています。
データ抽出ツールのユーザーインターフェース。
抽出定義の作成と管理に使用します。
バッチ処理 APIは
、抽出実行ジョブの送信と監視、および生成された出力ファイルの取得に使用されます。
OCIオブジェクトストレージは、
抽出されたデータの永続的な格納場所として使用されます。
簡略化した流れは次のようになります。
前提条件
始める前に、以下のものを用意してください。
- Fusion環境とそのベースURLへのアクセス権。
- データ抽出ツールが有効化され、設定されました。
- データ抽出ツールのユーザーインターフェースで既に作成済みの抽出定義。
- OAuth機密アプリケーションが作成されました
- IDCS OAuthの詳細:ホスト、クライアントID、クライアントシークレット、ユーザー名、パスワード。
- バッチジョブの送信および出力ファイルの取得に関する権限。
- 既存のOCIオブジェクトストレージバケット。
- そのバケットにオブジェクトをアップロードする権限を持つOCI SDK/構成プロファイル。
- Fusion、IDCS、およびOCIオブジェクトストレージへのネットワークアクセスが可能なランタイム環境。
抽出定義は、データ抽出ツールから作成する必要があります。UIで
+アイコンをクリックして新しい抽出を開始し、名前と必要に応じて説明を入力し、出力形式を選択し、必要なオブジェクトと属性を選択し、必要に応じてフィルタリングルールを定義して、「作成」をクリックして抽出定義を保存します。
1. ロード構成
まず、機密情報ではない設定と機密性の高い認証情報を分離することから始めましょう。
注:このコードはOracle AI Data Platform Workbenchを使用してテストしました。機密情報はすべて認証情報ストアに保存しました。
非機密値は環境変数またはデプロイメント構成に保存できます。
def mask(value: str, visible: int = 4) -> str:
if not value:
return "<empty>"
return "*" * max(0, len(value) - visible) + value[-visible:]</empty>BASE_URL = "https://<fusion host="">.fa.ocs.oraclecloud.com"
IDCS_HOST = aidputils.secrets.get(name="DataExtractionAPIs", key="IDCS_HOST")
IDCS_CLIENT_ID = aidputils.secrets.get(name="DataExtractionAPIs", key="IDCS_CLIENT_ID")
IDCS_CLIENT_SECRET = aidputils.secrets.get(name="DataExtractionAPIs", key="IDCS_CLIENT_SECRET")
IDCS_USERNAME = aidputils.secrets.get(name="DataExtractionAPIs", key="USERNAME")
IDCS_PASSWORD = aidputils.secrets.get(name="DataExtractionAPIs", key="password")
# <fusion hostname=""> if your fusion hostname is:
# https://fa-myfusion-test-saasfaprod1.fa.ocs.oraclecloud.com/
# you will put only myfusion-test
BATCH_SCOPE = os.getenv("BATCH_SCOPE", "urn:opc:resource:fusion:<fusion hostname="">:saas-batch/")
BUCKET_NAME = os.getenv("OCI_BUCKET_NAME", "bucket-data")
# This must match the extract definition name created in the Data Extraction Tool UI.
extract_name = os.getenv("EXTRACT_NAME", "ExampleCostDistributionExtract")
print(f"Configured host {BASE_URL}, client {mask(IDCS_CLIENT_ID)}")</fusion></fusion></fusion>コードスニペットには、元のコードには含まれていなかった余分な文字が含まれている場合があるので、コピーする際は十分注意してください。
2. OAuthトークンを要求する
パイプラインでは、データ抽出APIごとに個別のアクセストークンが必要です。再利用可能なトークン関数を使用することで、認証の一貫性を維持できます。
import requests
from requests.auth import HTTPBasicAuth
session = requests.Session()
session.headers.update({"Accept": "application/json"})
class HttpError(RuntimeError):
pass
def request_token(scope: str) -> str:
url = f"{IDCS_HOST.rstrip('/')}/oauth2/v1/token"
response = session.post(
url,
data={
"grant_type": "password",
"username": IDCS_USERNAME,
"password": IDCS_PASSWORD,
"scope": scope,
},
auth=HTTPBasicAuth(IDCS_CLIENT_ID, IDCS_CLIENT_SECRET),
headers={"Content-Type": "application/x-www-form-urlencoded;charset=UTF-8"},
timeout=30,
)
if response.status_code != 200:
raise HttpError(
f"Token request failed with status {response.status_code}: "
f"{response.text[:500]}"
)
token = response.json().get("access_token")
if not token:
raise HttpError("Token response did not include access_token")
return token次に、両方のトークンを要求します。
BATCH_TOKEN = request_token(BATCH_SCOPE)認証済みAPI呼び出しのためのヘルパー関数により、残りのコードが簡潔に保たれます。
def auth_headers(token: str, content_type: str = "application/json") -> dict:
return {
"Authorization": f"Bearer {token}",
"Accept": "application/json",
"Content-Type": content_type,
}3. 再利用可能なAPIリクエストヘルパーを追加する
エラー処理を一元化することで、API自動化の保守が容易になる。
def api_request(method: str, endpoint: str, token: str, **kwargs):
url = f"{BASE_URL.rstrip('/')}{endpoint}"
response = session.request(
method,
url,
headers=auth_headers(token),
timeout=60,
**kwargs,
)
if response.status_code >= 400:
raise HttpError(
f"{method} {endpoint} failed: "
f"{response.status_code} {response.text[:500]}"
)
return responseこのヘルパー関数は、URLの構築、ヘッダー、タイムアウト、および基本的なエラー報告を処理します。
4. 抽出を定義する
バッチ処理ジョブを送信する前に、データ抽出ツールのユーザーインターフェースで抽出定義を作成してください。
抽出定義では、エクスポートするデータと出力フォーマットを定義します。オブジェクト、属性、フォーマット、フィルタの選択をガイド付きで行えるため、UIを使用してこの定義を作成および管理することをお勧めします。
データ抽出ツールのユーザーインターフェースでは:
- アイコンをクリックして
+、新しい抽出を開始してください。 - 分かりやすい名前と、必要に応じて説明文を入力してください。
- 必要に応じて抽出日を定義してください。
- 出力形式を選択してください:CSVまたはJSON。
- オブジェクトと属性を選択します。
- 必要に応じて、データフィルタリングルールを設定できます。
- 抽出定義を保存するには、「作成」をクリックしてください。
抽出定義を作成したら、抽出定義名をメモしておいてください。自動化処理では、バッチ処理ジョブを実行する際にこの値を使用します。
extract_name = "ExampleCostDistributionExtract"5. バッチ処理ジョブを送信する
抽出データをバッチ処理で送信してください。
全文抽出の例:
schedule_name = f"{extract_name}Schedule"
extract_type = "Full"
#allowed values Full/Incremental
recurrence = "Immediate"
#allowed values Immediate/Simple/Hourly/Daily/Weekly/Monthly/Yearly
schedule_objst_payload = {
"serviceName": "boss",
"jobDefinitionName": "DataExport",
"description": f"{schedule_name}::{extract_name}::{extract_type}::{recurrence}",
"requestParameters": {
"submit.argument1": extract_name,
"submit.argument2": "Full Data Extract",
},
}増分抽出の例:
schedule_name = f"{extract_name}Schedule"
extract_type = "Incremental"
recurrence = "Hourly"
schedule_objst_payload = {
"serviceName": "boss",
"jobDefinitionName": "DataExport",
"description": f"{schedule_name}::{extract_name}::{extract_type}::{recurrence}",
"requestParameters": {
"submit.argument1": extract_name,
"submit.argument2": "Incremental Data Extract"
},
"runAtTimes": {
"fixedInterval": {
"interval": 1,
"timeUnit": "HOUR"
},
"startDate": "2026-05-15", #Date must be in the format YYYY-MM-DD
"endDate": "2026-05-15",
"startTime": "1200",
"endTime": "1500"
}
}fixedIntervalは、例えば30分ごとや150分ごとなど、固定レートスケジュールまたは固定間隔スケジュールを定義します。ここで、時間単位は分、時間、または日です。
timeUnitに指定できる値は「MINUTE」、「HOUR」、「DAY」です。
startDateとendDateは、スケジューリングルールが適用される全体の期間を定義するものであり、startDateは未来の日時を指定する必要があります。
startTimeとendTimeは、前提条件がすべて満たされた時点でスケジュールされた実行を開始する時間枠を定義します。デフォルトのstartTimeは午前0時(00:00)、デフォルトのendTimeは午後11時59分(23:59)です。これらの値は「HHMM」形式で指定します。
JobRequestを送信する:
schedule_objst_response = api_request(
"POST",
"/api/saas-batch/jobscheduler/v1/jobRequests",
BATCH_TOKEN,
json=schedule_objst_payload,
)
location = (
schedule_objst_response.headers.get("Location")
or schedule_objst_response.headers.get("location")
)
if not location:
raise RuntimeError("Batch Processing job request did not return a Location header")
job_request_id = location.rstrip("/").split("/")[-1]
print("Created Batch Processing jobRequestId:", job_request_id)これjobRequestIdは、ジョブの進行状況を監視し、出力ファイルを取得するために使用されるキー識別子です。
6. バッチ処理ジョブのステータスを確認する
ジョブが送信されたら、ジョブが終了状態に達するまでバッチ処理APIをポーリングします。
import time
terminal_statuses = {
"SUCCEEDED",
"COMPLETED",
"ERROR",
"FAILED",
"CANCELLED",
"PAUSED",
"WARNING",
}
while True:
batch_status_response = api_request(
"GET",
f"/api/saas-batch/jobscheduler/v1/jobRequests/{job_request_id}",
BATCH_TOKEN,
)
batch_status = batch_status_response.json()
status = (
batch_status.get("jobStatus")
or batch_status.get("jobDetails", {}).get("jobStatus")
or batch_status.get("jobProgress", {}).get("status")
)
print(f"Batch jobRequestId {job_request_id} status {status}")
if status in terminal_statuses:
break
time.sleep(10)7. 出力ファイルの一覧を表示する
ジョブ完了後、生成されたファイルを一覧表示します。
output_files_response = api_request(
"GET",
f"/api/saas-batch/jobfilemanager/v1/jobRequests/{job_request_id}/outputFiles",
BATCH_TOKEN,
)
output_files = output_files_response.json().get("items", [])
print("Found", len(output_files), "output file(s)")各項目には通常、ファイルに関するメタデータと、レスポンスコンテキスト内のダウンロードリンクが含まれています。
8. 出力ファイルをダウンロードする
import tempfile
from pathlib import Path
from urllib.parse import urlparse
def download_output_files(items, batch_token: str) -> list[Path]:
paths = []
tmp_dir = Path(tempfile.mkdtemp(prefix="bof_extract_"))
headers = {
"Authorization": f"Bearer {batch_token}",
"Accept": "application/octet-stream",
}
for item in items:
file_name = Path(item["fileName"]).name
href = item["$context"]["links"]["enclosure"]["href"]
parsed = urlparse(href)
if parsed.scheme != "https":
raise RuntimeError(f"Refusing non-HTTPS download URL: {href}")
destination = tmp_dir / file_name
with session.get(href, headers=headers, stream=True, timeout=120) as response:
response.raise_for_status()
with open(destination, "wb") as file:
for chunk in response.iter_content(chunk_size=1024 * 1024):
if chunk:
file.write(chunk)
print(f"Downloaded {file_name} to temporary storage")
paths.append(destination)
return pathsこの機能には、2つの重要な安全対策が含まれています。
まず、リモートファイル名からディレクトリパスを削除しますPath(item["fileName"]).name。次に、HTTPS以外のダウンロードURLを拒否します。
9. ZIPファイルを解凍する
import os
import zipfile
def extract_zip(zip_path: Path, extract_dir: Path) -> None:
extract_dir.mkdir(parents=True, exist_ok=True)
base = extract_dir.resolve()
with zipfile.ZipFile(zip_path, "r") as zip_file:
for member in zip_file.infolist():
target = (extract_dir / member.filename).resolve()
if not str(target).startswith(str(base) + os.sep):
raise RuntimeError(
f"Unsafe ZIP member path blocked: {member.filename}"
)
zip_file.extractall(extract_dir)次に、ダウンロードしたZIPファイルを解凍します。
extract_dir = Path("/tmp/extract_output")
downloaded_paths = download_output_files(output_files, BATCH_TOKEN)
for downloaded_path in downloaded_paths:
zip_path = Path(downloaded_path)
if zip_path.suffix.lower() == ".zip":
extract_zip(zip_path, extract_dir)10. ファイルをOCIオブジェクトストレージにアップロードする
OCI Python SDKを使用して、抽出したファイルをオブジェクトストレージにアップロードします。
import oci
profile = os.getenv("OCI_CONFIG_PROFILE", "DEFAULT")
config_path = os.getenv("OCI_CONFIG_PATH", "~/.oci/config")
config = oci.config.from_file(config_path, profile)
object_storage_client = oci.object_storage.ObjectStorageClient(config)
namespace = object_storage_client.get_namespace().data小さなアップロードヘルパーを作成します。
def upload_to_object_storage(file_path: Path, object_name: str | None = None):
object_name = object_name or file_path.name
with open(file_path, "rb") as file:
object_storage_client.put_object(
namespace_name=namespace,
bucket_name=BUCKET_NAME,
object_name=object_name,
put_object_body=file,
)
print(f"Uploaded object {object_name} to bucket {BUCKET_NAME}")抽出したすべてのファイルをアップロードしてください。
for file_path in extract_dir.rglob("*"):
if file_path.is_file():
upload_to_object_storage(file_path)まとめ
データ抽出ツールのユーザーインターフェースで抽出定義を作成および維持することで、セットアップ作業を簡素化し、ツールのガイド付きワークフローに沿ったものにすることができます。抽出定義が作成されると、セキュアなAPI駆動型パイプラインによって、運用上の労力と引き継ぎ作業を削減しながら、Fusionデータの実行、監視、ダウンロード、抽出、およびOCIオブジェクトストレージへのアップロードを自動化できます。



コメント
コメントを投稿